Generate accurate APA citations for free
- Knowledge Base
- APA Style 7th edition
- How to write an APA results section

Reporting Research Results in APA Style | Tips & Examples
Published on December 21, 2020 by Pritha Bhandari . Revised on January 17, 2024.
The results section of a quantitative research paper is where you summarize your data and report the findings of any relevant statistical analyses.
The APA manual provides rigorous guidelines for what to report in quantitative research papers in the fields of psychology, education, and other social sciences.
Use these standards to answer your research questions and report your data analyses in a complete and transparent way.
Instantly correct all language mistakes in your text
Upload your document to correct all your mistakes in minutes

Table of contents
What goes in your results section, introduce your data, summarize your data, report statistical results, presenting numbers effectively, what doesn’t belong in your results section, frequently asked questions about results in apa.
In APA style, the results section includes preliminary information about the participants and data, descriptive and inferential statistics, and the results of any exploratory analyses.
Include these in your results section:
- Participant flow and recruitment period. Report the number of participants at every stage of the study, as well as the dates when recruitment took place.
- Missing data . Identify the proportion of data that wasn’t included in your final analysis and state the reasons.
- Any adverse events. Make sure to report any unexpected events or side effects (for clinical studies).
- Descriptive statistics . Summarize the primary and secondary outcomes of the study.
- Inferential statistics , including confidence intervals and effect sizes. Address the primary and secondary research questions by reporting the detailed results of your main analyses.
- Results of subgroup or exploratory analyses, if applicable. Place detailed results in supplementary materials.
Write up the results in the past tense because you’re describing the outcomes of a completed research study.
Are your APA in-text citations flawless?
The AI-powered APA Citation Checker points out every error, tells you exactly what’s wrong, and explains how to fix it. Say goodbye to losing marks on your assignment!
Get started!

Before diving into your research findings, first describe the flow of participants at every stage of your study and whether any data were excluded from the final analysis.
Participant flow and recruitment period
It’s necessary to report any attrition, which is the decline in participants at every sequential stage of a study. That’s because an uneven number of participants across groups sometimes threatens internal validity and makes it difficult to compare groups. Be sure to also state all reasons for attrition.
If your study has multiple stages (e.g., pre-test, intervention, and post-test) and groups (e.g., experimental and control groups), a flow chart is the best way to report the number of participants in each group per stage and reasons for attrition.
Also report the dates for when you recruited participants or performed follow-up sessions.
Missing data
Another key issue is the completeness of your dataset. It’s necessary to report both the amount and reasons for data that was missing or excluded.
Data can become unusable due to equipment malfunctions, improper storage, unexpected events, participant ineligibility, and so on. For each case, state the reason why the data were unusable.
Some data points may be removed from the final analysis because they are outliers—but you must be able to justify how you decided what to exclude.
If you applied any techniques for overcoming or compensating for lost data, report those as well.
Adverse events
For clinical studies, report all events with serious consequences or any side effects that occured.
Descriptive statistics summarize your data for the reader. Present descriptive statistics for each primary, secondary, and subgroup analysis.
Don’t provide formulas or citations for commonly used statistics (e.g., standard deviation) – but do provide them for new or rare equations.
Descriptive statistics
The exact descriptive statistics that you report depends on the types of data in your study. Categorical variables can be reported using proportions, while quantitative data can be reported using means and standard deviations . For a large set of numbers, a table is the most effective presentation format.
Include sample sizes (overall and for each group) as well as appropriate measures of central tendency and variability for the outcomes in your results section. For every point estimate , add a clearly labelled measure of variability as well.
Be sure to note how you combined data to come up with variables of interest. For every variable of interest, explain how you operationalized it.
According to APA journal standards, it’s necessary to report all relevant hypothesis tests performed, estimates of effect sizes, and confidence intervals.
When reporting statistical results, you should first address primary research questions before moving onto secondary research questions and any exploratory or subgroup analyses.
Present the results of tests in the order that you performed them—report the outcomes of main tests before post-hoc tests, for example. Don’t leave out any relevant results, even if they don’t support your hypothesis.
Inferential statistics
For each statistical test performed, first restate the hypothesis , then state whether your hypothesis was supported and provide the outcomes that led you to that conclusion.
Report the following for each hypothesis test:
- the test statistic value,
- the degrees of freedom ,
- the exact p- value (unless it is less than 0.001),
- the magnitude and direction of the effect.
When reporting complex data analyses, such as factor analysis or multivariate analysis, present the models estimated in detail, and state the statistical software used. Make sure to report any violations of statistical assumptions or problems with estimation.
Effect sizes and confidence intervals
For each hypothesis test performed, you should present confidence intervals and estimates of effect sizes .
Confidence intervals are useful for showing the variability around point estimates. They should be included whenever you report population parameter estimates.
Effect sizes indicate how impactful the outcomes of a study are. But since they are estimates, it’s recommended that you also provide confidence intervals of effect sizes.
Subgroup or exploratory analyses
Briefly report the results of any other planned or exploratory analyses you performed. These may include subgroup analyses as well.
Subgroup analyses come with a high chance of false positive results, because performing a large number of comparison or correlation tests increases the chances of finding significant results.
If you find significant results in these analyses, make sure to appropriately report them as exploratory (rather than confirmatory) results to avoid overstating their importance.
While these analyses can be reported in less detail in the main text, you can provide the full analyses in supplementary materials.
Scribbr Citation Checker New
The AI-powered Citation Checker helps you avoid common mistakes such as:
- Missing commas and periods
- Incorrect usage of “et al.”
- Ampersands (&) in narrative citations
- Missing reference entries
To effectively present numbers, use a mix of text, tables , and figures where appropriate:
- To present three or fewer numbers, try a sentence ,
- To present between 4 and 20 numbers, try a table ,
- To present more than 20 numbers, try a figure .
Since these are general guidelines, use your own judgment and feedback from others for effective presentation of numbers.
Tables and figures should be numbered and have titles, along with relevant notes. Make sure to present data only once throughout the paper and refer to any tables and figures in the text.
Formatting statistics and numbers
It’s important to follow capitalization , italicization, and abbreviation rules when referring to statistics in your paper. There are specific format guidelines for reporting statistics in APA , as well as general rules about writing numbers .
If you are unsure of how to present specific symbols, look up the detailed APA guidelines or other papers in your field.
It’s important to provide a complete picture of your data analyses and outcomes in a concise way. For that reason, raw data and any interpretations of your results are not included in the results section.
It’s rarely appropriate to include raw data in your results section. Instead, you should always save the raw data securely and make them available and accessible to any other researchers who request them.
Making scientific research available to others is a key part of academic integrity and open science.
Interpretation or discussion of results
This belongs in your discussion section. Your results section is where you objectively report all relevant findings and leave them open for interpretation by readers.
While you should state whether the findings of statistical tests lend support to your hypotheses, refrain from forming conclusions to your research questions in the results section.
Explanation of how statistics tests work
For the sake of concise writing, you can safely assume that readers of your paper have professional knowledge of how statistical inferences work.
In an APA results section , you should generally report the following:
- Participant flow and recruitment period.
- Missing data and any adverse events.
- Descriptive statistics about your samples.
- Inferential statistics , including confidence intervals and effect sizes.
- Results of any subgroup or exploratory analyses, if applicable.
According to the APA guidelines, you should report enough detail on inferential statistics so that your readers understand your analyses.
- the test statistic value
- the degrees of freedom
- the exact p value (unless it is less than 0.001)
- the magnitude and direction of the effect
You should also present confidence intervals and estimates of effect sizes where relevant.
In APA style, statistics can be presented in the main text or as tables or figures . To decide how to present numbers, you can follow APA guidelines:
- To present three or fewer numbers, try a sentence,
- To present between 4 and 20 numbers, try a table,
- To present more than 20 numbers, try a figure.
Results are usually written in the past tense , because they are describing the outcome of completed actions.
The results chapter or section simply and objectively reports what you found, without speculating on why you found these results. The discussion interprets the meaning of the results, puts them in context, and explains why they matter.
In qualitative research , results and discussion are sometimes combined. But in quantitative research , it’s considered important to separate the objective results from your interpretation of them.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2024, January 17). Reporting Research Results in APA Style | Tips & Examples. Scribbr. Retrieved August 27, 2024, from https://www.scribbr.com/apa-style/results-section/
Is this article helpful?

Pritha Bhandari
Other students also liked, how to write an apa methods section, how to format tables and figures in apa style, reporting statistics in apa style | guidelines & examples, scribbr apa citation checker.
An innovative new tool that checks your APA citations with AI software. Say goodbye to inaccurate citations!

- Langson Library
- Science Library
- Grunigen Medical Library
- Law Library
- Connect From Off-Campus
- Accessibility
- Gateway Study Center
Email this link
Writing a scientific paper.
- Writing a lab report
- INTRODUCTION
Writing a "good" results section
Figures and Captions in Lab Reports
"Results Checklist" from: How to Write a Good Scientific Paper. Chris A. Mack. SPIE. 2018.
Additional tips for results sections.
- LITERATURE CITED
- Bibliography of guides to scientific writing and presenting
- Peer Review
- Presentations
- Lab Report Writing Guides on the Web
This is the core of the paper. Don't start the results sections with methods you left out of the Materials and Methods section. You need to give an overall description of the experiments and present the data you found.
- Factual statements supported by evidence. Short and sweet without excess words
- Present representative data rather than endlessly repetitive data
- Discuss variables only if they had an effect (positive or negative)
- Use meaningful statistics
- Avoid redundancy. If it is in the tables or captions you may not need to repeat it
A short article by Dr. Brett Couch and Dr. Deena Wassenberg, Biology Program, University of Minnesota
- Present the results of the paper, in logical order, using tables and graphs as necessary.
- Explain the results and show how they help to answer the research questions posed in the Introduction. Evidence does not explain itself; the results must be presented and then explained.
- Avoid: presenting results that are never discussed; presenting results in chronological order rather than logical order; ignoring results that do not support the conclusions;
- Number tables and figures separately beginning with 1 (i.e. Table 1, Table 2, Figure 1, etc.).
- Do not attempt to evaluate the results in this section. Report only what you found; hold all discussion of the significance of the results for the Discussion section.
- It is not necessary to describe every step of your statistical analyses. Scientists understand all about null hypotheses, rejection rules, and so forth and do not need to be reminded of them. Just say something like, "Honeybees did not use the flowers in proportion to their availability (X2 = 7.9, p<0.05, d.f.= 4, chi-square test)." Likewise, cite tables and figures without describing in detail how the data were manipulated. Explanations of this sort should appear in a legend or caption written on the same page as the figure or table.
- You must refer in the text to each figure or table you include in your paper.
- Tables generally should report summary-level data, such as means ± standard deviations, rather than all your raw data. A long list of all your individual observations will mean much less than a few concise, easy-to-read tables or figures that bring out the main findings of your study.
- Only use a figure (graph) when the data lend themselves to a good visual representation. Avoid using figures that show too many variables or trends at once, because they can be hard to understand.
From: https://writingcenter.gmu.edu/guides/imrad-results-discussion
- << Previous: METHODS
- Next: DISCUSSION >>
- Last Updated: Aug 4, 2023 9:33 AM
- URL: https://guides.lib.uci.edu/scientificwriting
Off-campus? Please use the Software VPN and choose the group UCIFull to access licensed content. For more information, please Click here
Software VPN is not available for guests, so they may not have access to some content when connecting from off-campus.
- Research Process
- Manuscript Preparation
- Manuscript Review
- Publication Process
- Publication Recognition
- Language Editing Services
- Translation Services

How to Write the Results Section: Guide to Structure and Key Points
- 4 minute read
- 76.9K views
Table of Contents
The ‘ Results’ section of a research paper, like the ‘Introduction’ and other key parts, attracts significant attention from editors, reviewers, and readers. The reason lies in its critical role — that of revealing the key findings of a study and demonstrating how your research fills a knowledge gap in your field of study. Given its importance, crafting a clear and logically structured results section is essential.
In this article, we will discuss the key elements of an effective results section and share strategies for making it concise and engaging. We hope this guide will help you quickly grasp ways of writing the results section, avoid common pitfalls, and make your writing process more efficient and effective.
Structure of the results section
Briefly restate the research topic in the introduction : Although the main purpose of the results section in a research paper is to list the notable findings of a study, it is customary to start with a brief repetition of the research question. This helps refocus the reader, allowing them to better appreciate the relevance of the findings. Additionally, restating the research question establishes a connection to the previous section of the paper, creating a smoother flow of information.
Systematically present your research findings : Address the primary research question first, followed by the secondary research questions. If your research addresses multiple questions, mention the findings related to each one individually to ensure clarity and coherence.
Represent your results visually: Graphs, tables, and other figures can help illustrate the findings of your paper, especially if there is a large amount of data in the results. As a rule of thumb, use a visual medium like a graph or a table if you wish to present three or more statistical values simultaneously.
Graphical or tabular representations of data can also make your results section more visually appealing. Remember, an appealing and well-organized results section can help peer reviewers better understand the merits of your research, thereby increasing your chances of publication.
Practical guidance for writing an effective ‘Results’ section
- Always use simple and plain language. Avoid the use of uncertain or unclear expressions.
- The findings of the study must be expressed in an objective and unbiased manner. While it is acceptable to correlate certain findings , it is best to avoid over-interpreting the results. In addition, avoid using subjective or emotional words , such as “interestingly” or “unfortunately”, to describe the results as this may cause readers to doubt the objectivity of the paper.
- The content balances simplicity with comprehensiveness . For statistical data, simply describe the relevant tests and explain their results without mentioning raw data. If the study involves multiple hypotheses, describe the results for each one separately to avoid confusion and aid understanding. To enhance credibility, e nsure that negative results , if any, are included in this section, even if they do not support the research hypothesis.
- Wherever possible, use illustrations like tables, figures, charts, or other visual representations to highlight the results of your research paper. Mention these illustrations in the text, but do not repeat the information that they convey ¹ .
Difference between data, results, and discussion sections
Data , results, and discussion sections all communicate the findings of a study, but each serves a distinct purpose with varying levels of interpretation.
In the results section , one cannot provide data without interpreting its relevance or make statements without citing data ² . In a sense, the results section does not draw connections between different data points. Therefore, there is a certain level of interpretation involved in drawing results out of data.
(The example is intended to showcase how the visual elements and text in the results section complement each other ³ . The academic viewpoints included in the illustrative screenshots should not be used as references.)
The discussion section allows authors even more interpretive freedom compared to the results section. Here, data and patterns within the data are compared with the findings from other studies to make more generalized points. Unlike the results section , which focuses purely on factual data, the discussion section touches upon hypothetical information, drawing conjectures and suggesting future directions for research.
The ‘ Results’ section serves as the core of a research paper, capturing readers’ attention and providing insights into the study’s essence. Regardless of the subject of your research paper, a well-written results section can generate interest in your research. By following the tips outlined here, you can create a results section that effectively communicates your finding and invites further exploration. Remember, clarity is the key, and with the right approach, your results section can guide readers through the intricacies of your research.
Professionals at Elsevier Language Services know the secret to writing a well-balanced results section. With their expert suggestions, you can ensure that your findings come across clearly to the reader. To maximize your chances of publication, reach out to Elsevier Language Services today !
Type in wordcount for Standard Total: USD EUR JPY Follow this link if your manuscript is longer than 12,000 words. Upload
Reference
- Cetin, S., & Hackam, D. J. (2005). An approach to the writing of a scientific manuscript. Journal of Surgical Research, 128(2), 165–167. https://doi.org/10.1016/j.jss.2005.07.002
- Bahadoran, Z., Mirmiran, P., Zadeh-Vakili, A., Hosseinpanah, F., & Ghasemi, A. (2019). The Principles of Biomedical Scientific Writing: Results. International Journal of Endocrinology and Metabolism/International Journal of Endocrinology and Metabolism., In Press (In Press). https://doi.org/10.5812/ijem.92113
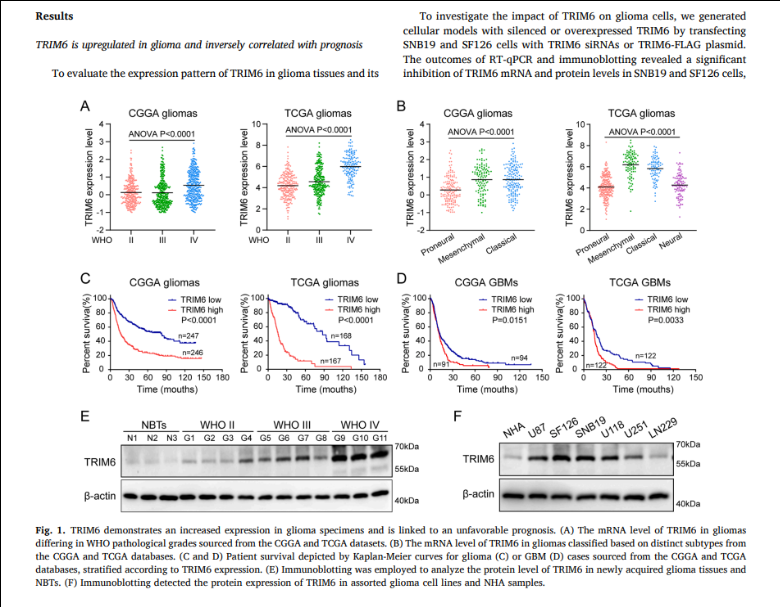
- Guo, J., Wang, J., Zhang, P., Wen, P., Zhang, S., Dong, X., & Dong, J. (2024). TRIM6 promotes glioma malignant progression by enhancing FOXO3A ubiquitination and degradation. Translational Oncology, 46, 101999. https://doi.org/10.1016/j.tranon.2024.101999

Writing a good review article

Why is data validation important in research?
You may also like.

Submission 101: What format should be used for academic papers?

Page-Turner Articles are More Than Just Good Arguments: Be Mindful of Tone and Structure!

A Must-see for Researchers! How to Ensure Inclusivity in Your Scientific Writing

Make Hook, Line, and Sinker: The Art of Crafting Engaging Introductions

Can Describing Study Limitations Improve the Quality of Your Paper?

A Guide to Crafting Shorter, Impactful Sentences in Academic Writing

6 Steps to Write an Excellent Discussion in Your Manuscript

How to Write Clear and Crisp Civil Engineering Papers? Here are 5 Key Tips to Consider
Input your search keywords and press Enter.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
How to Write an Effective Results Section
Affiliation.
- 1 Rothman Orthopaedics Institute, Philadelphia, PA.
- PMID: 31145152
- DOI: 10.1097/BSD.0000000000000845
Developing a well-written research paper is an important step in completing a scientific study. This paper is where the principle investigator and co-authors report the purpose, methods, findings, and conclusions of the study. A key element of writing a research paper is to clearly and objectively report the study's findings in the Results section. The Results section is where the authors inform the readers about the findings from the statistical analysis of the data collected to operationalize the study hypothesis, optimally adding novel information to the collective knowledge on the subject matter. By utilizing clear, concise, and well-organized writing techniques and visual aids in the reporting of the data, the author is able to construct a case for the research question at hand even without interpreting the data.
PubMed Disclaimer
Similar articles
- Rules to be adopted for publishing a scientific paper. Picardi N. Picardi N. Ann Ital Chir. 2016;87:1-3. Ann Ital Chir. 2016. PMID: 28474609
- How to Write Effective Discussion and Conclusion Sections. Makar G, Foltz C, Lendner M, Vaccaro AR. Makar G, et al. Clin Spine Surg. 2018 Oct;31(8):345-346. doi: 10.1097/BSD.0000000000000687. Clin Spine Surg. 2018. PMID: 29979216
- The rites of writing papers: steps to successful publishing for psychiatrists. Brakoulias V, Macfarlane MD, Looi JC. Brakoulias V, et al. Australas Psychiatry. 2015 Feb;23(1):32-6. doi: 10.1177/1039856214560180. Epub 2014 Dec 2. Australas Psychiatry. 2015. PMID: 25469001
- How to write a research paper. Alexandrov AV. Alexandrov AV. Cerebrovasc Dis. 2004;18(2):135-8. doi: 10.1159/000079266. Epub 2004 Jun 23. Cerebrovasc Dis. 2004. PMID: 15218279 Review.
- How to write an original radiological research manuscript. Bannas P, Reeder SB. Bannas P, et al. Eur Radiol. 2017 Nov;27(11):4455-4460. doi: 10.1007/s00330-017-4879-8. Epub 2017 Jun 14. Eur Radiol. 2017. PMID: 28616726 Free PMC article. Review.
- Essential Guide to Manuscript Writing for Academic Dummies: An Editor's Perspective. Aga SS, Nissar S. Aga SS, et al. Biochem Res Int. 2022 Sep 1;2022:1492058. doi: 10.1155/2022/1492058. eCollection 2022. Biochem Res Int. 2022. PMID: 36092536 Free PMC article. Review.
- Search in MeSH
LinkOut - more resources
Full text sources.
- Ovid Technologies, Inc.
- Wolters Kluwer

- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 11: Presenting Your Research
Writing a Research Report in American Psychological Association (APA) Style
Learning Objectives
- Identify the major sections of an APA-style research report and the basic contents of each section.
- Plan and write an effective APA-style research report.
In this section, we look at how to write an APA-style empirical research report , an article that presents the results of one or more new studies. Recall that the standard sections of an empirical research report provide a kind of outline. Here we consider each of these sections in detail, including what information it contains, how that information is formatted and organized, and tips for writing each section. At the end of this section is a sample APA-style research report that illustrates many of these principles.
Sections of a Research Report
Title page and abstract.
An APA-style research report begins with a title page . The title is centred in the upper half of the page, with each important word capitalized. The title should clearly and concisely (in about 12 words or fewer) communicate the primary variables and research questions. This sometimes requires a main title followed by a subtitle that elaborates on the main title, in which case the main title and subtitle are separated by a colon. Here are some titles from recent issues of professional journals published by the American Psychological Association.
- Sex Differences in Coping Styles and Implications for Depressed Mood
- Effects of Aging and Divided Attention on Memory for Items and Their Contexts
- Computer-Assisted Cognitive Behavioural Therapy for Child Anxiety: Results of a Randomized Clinical Trial
- Virtual Driving and Risk Taking: Do Racing Games Increase Risk-Taking Cognitions, Affect, and Behaviour?
Below the title are the authors’ names and, on the next line, their institutional affiliation—the university or other institution where the authors worked when they conducted the research. As we have already seen, the authors are listed in an order that reflects their contribution to the research. When multiple authors have made equal contributions to the research, they often list their names alphabetically or in a randomly determined order.
In some areas of psychology, the titles of many empirical research reports are informal in a way that is perhaps best described as “cute.” They usually take the form of a play on words or a well-known expression that relates to the topic under study. Here are some examples from recent issues of the Journal Psychological Science .
- “Smells Like Clean Spirit: Nonconscious Effects of Scent on Cognition and Behavior”
- “Time Crawls: The Temporal Resolution of Infants’ Visual Attention”
- “Scent of a Woman: Men’s Testosterone Responses to Olfactory Ovulation Cues”
- “Apocalypse Soon?: Dire Messages Reduce Belief in Global Warming by Contradicting Just-World Beliefs”
- “Serial vs. Parallel Processing: Sometimes They Look Like Tweedledum and Tweedledee but They Can (and Should) Be Distinguished”
- “How Do I Love Thee? Let Me Count the Words: The Social Effects of Expressive Writing”
Individual researchers differ quite a bit in their preference for such titles. Some use them regularly, while others never use them. What might be some of the pros and cons of using cute article titles?
For articles that are being submitted for publication, the title page also includes an author note that lists the authors’ full institutional affiliations, any acknowledgments the authors wish to make to agencies that funded the research or to colleagues who commented on it, and contact information for the authors. For student papers that are not being submitted for publication—including theses—author notes are generally not necessary.
The abstract is a summary of the study. It is the second page of the manuscript and is headed with the word Abstract . The first line is not indented. The abstract presents the research question, a summary of the method, the basic results, and the most important conclusions. Because the abstract is usually limited to about 200 words, it can be a challenge to write a good one.
Introduction
The introduction begins on the third page of the manuscript. The heading at the top of this page is the full title of the manuscript, with each important word capitalized as on the title page. The introduction includes three distinct subsections, although these are typically not identified by separate headings. The opening introduces the research question and explains why it is interesting, the literature review discusses relevant previous research, and the closing restates the research question and comments on the method used to answer it.
The Opening
The opening , which is usually a paragraph or two in length, introduces the research question and explains why it is interesting. To capture the reader’s attention, researcher Daryl Bem recommends starting with general observations about the topic under study, expressed in ordinary language (not technical jargon)—observations that are about people and their behaviour (not about researchers or their research; Bem, 2003 [1] ). Concrete examples are often very useful here. According to Bem, this would be a poor way to begin a research report:
Festinger’s theory of cognitive dissonance received a great deal of attention during the latter part of the 20th century (p. 191)
The following would be much better:
The individual who holds two beliefs that are inconsistent with one another may feel uncomfortable. For example, the person who knows that he or she enjoys smoking but believes it to be unhealthy may experience discomfort arising from the inconsistency or disharmony between these two thoughts or cognitions. This feeling of discomfort was called cognitive dissonance by social psychologist Leon Festinger (1957), who suggested that individuals will be motivated to remove this dissonance in whatever way they can (p. 191).
After capturing the reader’s attention, the opening should go on to introduce the research question and explain why it is interesting. Will the answer fill a gap in the literature? Will it provide a test of an important theory? Does it have practical implications? Giving readers a clear sense of what the research is about and why they should care about it will motivate them to continue reading the literature review—and will help them make sense of it.
Breaking the Rules
Researcher Larry Jacoby reported several studies showing that a word that people see or hear repeatedly can seem more familiar even when they do not recall the repetitions—and that this tendency is especially pronounced among older adults. He opened his article with the following humourous anecdote:
A friend whose mother is suffering symptoms of Alzheimer’s disease (AD) tells the story of taking her mother to visit a nursing home, preliminary to her mother’s moving there. During an orientation meeting at the nursing home, the rules and regulations were explained, one of which regarded the dining room. The dining room was described as similar to a fine restaurant except that tipping was not required. The absence of tipping was a central theme in the orientation lecture, mentioned frequently to emphasize the quality of care along with the advantages of having paid in advance. At the end of the meeting, the friend’s mother was asked whether she had any questions. She replied that she only had one question: “Should I tip?” (Jacoby, 1999, p. 3)
Although both humour and personal anecdotes are generally discouraged in APA-style writing, this example is a highly effective way to start because it both engages the reader and provides an excellent real-world example of the topic under study.
The Literature Review
Immediately after the opening comes the literature review , which describes relevant previous research on the topic and can be anywhere from several paragraphs to several pages in length. However, the literature review is not simply a list of past studies. Instead, it constitutes a kind of argument for why the research question is worth addressing. By the end of the literature review, readers should be convinced that the research question makes sense and that the present study is a logical next step in the ongoing research process.
Like any effective argument, the literature review must have some kind of structure. For example, it might begin by describing a phenomenon in a general way along with several studies that demonstrate it, then describing two or more competing theories of the phenomenon, and finally presenting a hypothesis to test one or more of the theories. Or it might describe one phenomenon, then describe another phenomenon that seems inconsistent with the first one, then propose a theory that resolves the inconsistency, and finally present a hypothesis to test that theory. In applied research, it might describe a phenomenon or theory, then describe how that phenomenon or theory applies to some important real-world situation, and finally suggest a way to test whether it does, in fact, apply to that situation.
Looking at the literature review in this way emphasizes a few things. First, it is extremely important to start with an outline of the main points that you want to make, organized in the order that you want to make them. The basic structure of your argument, then, should be apparent from the outline itself. Second, it is important to emphasize the structure of your argument in your writing. One way to do this is to begin the literature review by summarizing your argument even before you begin to make it. “In this article, I will describe two apparently contradictory phenomena, present a new theory that has the potential to resolve the apparent contradiction, and finally present a novel hypothesis to test the theory.” Another way is to open each paragraph with a sentence that summarizes the main point of the paragraph and links it to the preceding points. These opening sentences provide the “transitions” that many beginning researchers have difficulty with. Instead of beginning a paragraph by launching into a description of a previous study, such as “Williams (2004) found that…,” it is better to start by indicating something about why you are describing this particular study. Here are some simple examples:
Another example of this phenomenon comes from the work of Williams (2004).
Williams (2004) offers one explanation of this phenomenon.
An alternative perspective has been provided by Williams (2004).
We used a method based on the one used by Williams (2004).
Finally, remember that your goal is to construct an argument for why your research question is interesting and worth addressing—not necessarily why your favourite answer to it is correct. In other words, your literature review must be balanced. If you want to emphasize the generality of a phenomenon, then of course you should discuss various studies that have demonstrated it. However, if there are other studies that have failed to demonstrate it, you should discuss them too. Or if you are proposing a new theory, then of course you should discuss findings that are consistent with that theory. However, if there are other findings that are inconsistent with it, again, you should discuss them too. It is acceptable to argue that the balance of the research supports the existence of a phenomenon or is consistent with a theory (and that is usually the best that researchers in psychology can hope for), but it is not acceptable to ignore contradictory evidence. Besides, a large part of what makes a research question interesting is uncertainty about its answer.
The Closing
The closing of the introduction—typically the final paragraph or two—usually includes two important elements. The first is a clear statement of the main research question or hypothesis. This statement tends to be more formal and precise than in the opening and is often expressed in terms of operational definitions of the key variables. The second is a brief overview of the method and some comment on its appropriateness. Here, for example, is how Darley and Latané (1968) [2] concluded the introduction to their classic article on the bystander effect:
These considerations lead to the hypothesis that the more bystanders to an emergency, the less likely, or the more slowly, any one bystander will intervene to provide aid. To test this proposition it would be necessary to create a situation in which a realistic “emergency” could plausibly occur. Each subject should also be blocked from communicating with others to prevent his getting information about their behaviour during the emergency. Finally, the experimental situation should allow for the assessment of the speed and frequency of the subjects’ reaction to the emergency. The experiment reported below attempted to fulfill these conditions. (p. 378)
Thus the introduction leads smoothly into the next major section of the article—the method section.
The method section is where you describe how you conducted your study. An important principle for writing a method section is that it should be clear and detailed enough that other researchers could replicate the study by following your “recipe.” This means that it must describe all the important elements of the study—basic demographic characteristics of the participants, how they were recruited, whether they were randomly assigned, how the variables were manipulated or measured, how counterbalancing was accomplished, and so on. At the same time, it should avoid irrelevant details such as the fact that the study was conducted in Classroom 37B of the Industrial Technology Building or that the questionnaire was double-sided and completed using pencils.
The method section begins immediately after the introduction ends with the heading “Method” (not “Methods”) centred on the page. Immediately after this is the subheading “Participants,” left justified and in italics. The participants subsection indicates how many participants there were, the number of women and men, some indication of their age, other demographics that may be relevant to the study, and how they were recruited, including any incentives given for participation.

After the participants section, the structure can vary a bit. Figure 11.1 shows three common approaches. In the first, the participants section is followed by a design and procedure subsection, which describes the rest of the method. This works well for methods that are relatively simple and can be described adequately in a few paragraphs. In the second approach, the participants section is followed by separate design and procedure subsections. This works well when both the design and the procedure are relatively complicated and each requires multiple paragraphs.
What is the difference between design and procedure? The design of a study is its overall structure. What were the independent and dependent variables? Was the independent variable manipulated, and if so, was it manipulated between or within subjects? How were the variables operationally defined? The procedure is how the study was carried out. It often works well to describe the procedure in terms of what the participants did rather than what the researchers did. For example, the participants gave their informed consent, read a set of instructions, completed a block of four practice trials, completed a block of 20 test trials, completed two questionnaires, and were debriefed and excused.
In the third basic way to organize a method section, the participants subsection is followed by a materials subsection before the design and procedure subsections. This works well when there are complicated materials to describe. This might mean multiple questionnaires, written vignettes that participants read and respond to, perceptual stimuli, and so on. The heading of this subsection can be modified to reflect its content. Instead of “Materials,” it can be “Questionnaires,” “Stimuli,” and so on.
The results section is where you present the main results of the study, including the results of the statistical analyses. Although it does not include the raw data—individual participants’ responses or scores—researchers should save their raw data and make them available to other researchers who request them. Several journals now encourage the open sharing of raw data online.
Although there are no standard subsections, it is still important for the results section to be logically organized. Typically it begins with certain preliminary issues. One is whether any participants or responses were excluded from the analyses and why. The rationale for excluding data should be described clearly so that other researchers can decide whether it is appropriate. A second preliminary issue is how multiple responses were combined to produce the primary variables in the analyses. For example, if participants rated the attractiveness of 20 stimulus people, you might have to explain that you began by computing the mean attractiveness rating for each participant. Or if they recalled as many items as they could from study list of 20 words, did you count the number correctly recalled, compute the percentage correctly recalled, or perhaps compute the number correct minus the number incorrect? A third preliminary issue is the reliability of the measures. This is where you would present test-retest correlations, Cronbach’s α, or other statistics to show that the measures are consistent across time and across items. A final preliminary issue is whether the manipulation was successful. This is where you would report the results of any manipulation checks.
The results section should then tackle the primary research questions, one at a time. Again, there should be a clear organization. One approach would be to answer the most general questions and then proceed to answer more specific ones. Another would be to answer the main question first and then to answer secondary ones. Regardless, Bem (2003) [3] suggests the following basic structure for discussing each new result:
- Remind the reader of the research question.
- Give the answer to the research question in words.
- Present the relevant statistics.
- Qualify the answer if necessary.
- Summarize the result.
Notice that only Step 3 necessarily involves numbers. The rest of the steps involve presenting the research question and the answer to it in words. In fact, the basic results should be clear even to a reader who skips over the numbers.
The discussion is the last major section of the research report. Discussions usually consist of some combination of the following elements:
- Summary of the research
- Theoretical implications
- Practical implications
- Limitations
- Suggestions for future research
The discussion typically begins with a summary of the study that provides a clear answer to the research question. In a short report with a single study, this might require no more than a sentence. In a longer report with multiple studies, it might require a paragraph or even two. The summary is often followed by a discussion of the theoretical implications of the research. Do the results provide support for any existing theories? If not, how can they be explained? Although you do not have to provide a definitive explanation or detailed theory for your results, you at least need to outline one or more possible explanations. In applied research—and often in basic research—there is also some discussion of the practical implications of the research. How can the results be used, and by whom, to accomplish some real-world goal?
The theoretical and practical implications are often followed by a discussion of the study’s limitations. Perhaps there are problems with its internal or external validity. Perhaps the manipulation was not very effective or the measures not very reliable. Perhaps there is some evidence that participants did not fully understand their task or that they were suspicious of the intent of the researchers. Now is the time to discuss these issues and how they might have affected the results. But do not overdo it. All studies have limitations, and most readers will understand that a different sample or different measures might have produced different results. Unless there is good reason to think they would have, however, there is no reason to mention these routine issues. Instead, pick two or three limitations that seem like they could have influenced the results, explain how they could have influenced the results, and suggest ways to deal with them.
Most discussions end with some suggestions for future research. If the study did not satisfactorily answer the original research question, what will it take to do so? What new research questions has the study raised? This part of the discussion, however, is not just a list of new questions. It is a discussion of two or three of the most important unresolved issues. This means identifying and clarifying each question, suggesting some alternative answers, and even suggesting ways they could be studied.
Finally, some researchers are quite good at ending their articles with a sweeping or thought-provoking conclusion. Darley and Latané (1968) [4] , for example, ended their article on the bystander effect by discussing the idea that whether people help others may depend more on the situation than on their personalities. Their final sentence is, “If people understand the situational forces that can make them hesitate to intervene, they may better overcome them” (p. 383). However, this kind of ending can be difficult to pull off. It can sound overreaching or just banal and end up detracting from the overall impact of the article. It is often better simply to end when you have made your final point (although you should avoid ending on a limitation).
The references section begins on a new page with the heading “References” centred at the top of the page. All references cited in the text are then listed in the format presented earlier. They are listed alphabetically by the last name of the first author. If two sources have the same first author, they are listed alphabetically by the last name of the second author. If all the authors are the same, then they are listed chronologically by the year of publication. Everything in the reference list is double-spaced both within and between references.
Appendices, Tables, and Figures
Appendices, tables, and figures come after the references. An appendix is appropriate for supplemental material that would interrupt the flow of the research report if it were presented within any of the major sections. An appendix could be used to present lists of stimulus words, questionnaire items, detailed descriptions of special equipment or unusual statistical analyses, or references to the studies that are included in a meta-analysis. Each appendix begins on a new page. If there is only one, the heading is “Appendix,” centred at the top of the page. If there is more than one, the headings are “Appendix A,” “Appendix B,” and so on, and they appear in the order they were first mentioned in the text of the report.
After any appendices come tables and then figures. Tables and figures are both used to present results. Figures can also be used to illustrate theories (e.g., in the form of a flowchart), display stimuli, outline procedures, and present many other kinds of information. Each table and figure appears on its own page. Tables are numbered in the order that they are first mentioned in the text (“Table 1,” “Table 2,” and so on). Figures are numbered the same way (“Figure 1,” “Figure 2,” and so on). A brief explanatory title, with the important words capitalized, appears above each table. Each figure is given a brief explanatory caption, where (aside from proper nouns or names) only the first word of each sentence is capitalized. More details on preparing APA-style tables and figures are presented later in the book.
Sample APA-Style Research Report
Figures 11.2, 11.3, 11.4, and 11.5 show some sample pages from an APA-style empirical research report originally written by undergraduate student Tomoe Suyama at California State University, Fresno. The main purpose of these figures is to illustrate the basic organization and formatting of an APA-style empirical research report, although many high-level and low-level style conventions can be seen here too.

Key Takeaways
- An APA-style empirical research report consists of several standard sections. The main ones are the abstract, introduction, method, results, discussion, and references.
- The introduction consists of an opening that presents the research question, a literature review that describes previous research on the topic, and a closing that restates the research question and comments on the method. The literature review constitutes an argument for why the current study is worth doing.
- The method section describes the method in enough detail that another researcher could replicate the study. At a minimum, it consists of a participants subsection and a design and procedure subsection.
- The results section describes the results in an organized fashion. Each primary result is presented in terms of statistical results but also explained in words.
- The discussion typically summarizes the study, discusses theoretical and practical implications and limitations of the study, and offers suggestions for further research.
- Practice: Look through an issue of a general interest professional journal (e.g., Psychological Science ). Read the opening of the first five articles and rate the effectiveness of each one from 1 ( very ineffective ) to 5 ( very effective ). Write a sentence or two explaining each rating.
- Practice: Find a recent article in a professional journal and identify where the opening, literature review, and closing of the introduction begin and end.
- Practice: Find a recent article in a professional journal and highlight in a different colour each of the following elements in the discussion: summary, theoretical implications, practical implications, limitations, and suggestions for future research.
Long Descriptions
Figure 11.1 long description: Table showing three ways of organizing an APA-style method section.
In the simple method, there are two subheadings: “Participants” (which might begin “The participants were…”) and “Design and procedure” (which might begin “There were three conditions…”).
In the typical method, there are three subheadings: “Participants” (“The participants were…”), “Design” (“There were three conditions…”), and “Procedure” (“Participants viewed each stimulus on the computer screen…”).
In the complex method, there are four subheadings: “Participants” (“The participants were…”), “Materials” (“The stimuli were…”), “Design” (“There were three conditions…”), and “Procedure” (“Participants viewed each stimulus on the computer screen…”). [Return to Figure 11.1]
- Bem, D. J. (2003). Writing the empirical journal article. In J. M. Darley, M. P. Zanna, & H. R. Roediger III (Eds.), The compleat academic: A practical guide for the beginning social scientist (2nd ed.). Washington, DC: American Psychological Association. ↵
- Darley, J. M., & Latané, B. (1968). Bystander intervention in emergencies: Diffusion of responsibility. Journal of Personality and Social Psychology, 4 , 377–383. ↵
A type of research article which describes one or more new empirical studies conducted by the authors.
The page at the beginning of an APA-style research report containing the title of the article, the authors’ names, and their institutional affiliation.
A summary of a research study.
The third page of a manuscript containing the research question, the literature review, and comments about how to answer the research question.
An introduction to the research question and explanation for why this question is interesting.
A description of relevant previous research on the topic being discusses and an argument for why the research is worth addressing.
The end of the introduction, where the research question is reiterated and the method is commented upon.
The section of a research report where the method used to conduct the study is described.
The main results of the study, including the results from statistical analyses, are presented in a research article.
Section of a research report that summarizes the study's results and interprets them by referring back to the study's theoretical background.
Part of a research report which contains supplemental material.
Research Methods in Psychology - 2nd Canadian Edition Copyright © 2015 by Paul C. Price, Rajiv Jhangiani, & I-Chant A. Chiang is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Guide to Writing the Results and Discussion Sections of a Scientific Article
A quality research paper has both the qualities of in-depth research and good writing ( Bordage, 2001 ). In addition, a research paper must be clear, concise, and effective when presenting the information in an organized structure with a logical manner ( Sandercock, 2013 ).
In this article, we will take a closer look at the results and discussion section. Composing each of these carefully with sufficient data and well-constructed arguments can help improve your paper overall.

The results section of your research paper contains a description about the main findings of your research, whereas the discussion section interprets the results for readers and provides the significance of the findings. The discussion should not repeat the results.
Let’s dive in a little deeper about how to properly, and clearly organize each part.

How to Organize the Results Section
Since your results follow your methods, you’ll want to provide information about what you discovered from the methods you used, such as your research data. In other words, what were the outcomes of the methods you used?
You may also include information about the measurement of your data, variables, treatments, and statistical analyses.
To start, organize your research data based on how important those are in relation to your research questions. This section should focus on showing major results that support or reject your research hypothesis. Include your least important data as supplemental materials when submitting to the journal.
The next step is to prioritize your research data based on importance – focusing heavily on the information that directly relates to your research questions using the subheadings.
The organization of the subheadings for the results section usually mirrors the methods section. It should follow a logical and chronological order.
Subheading organization
Subheadings within your results section are primarily going to detail major findings within each important experiment. And the first paragraph of your results section should be dedicated to your main findings (findings that answer your overall research question and lead to your conclusion) (Hofmann, 2013).
In the book “Writing in the Biological Sciences,” author Angelika Hofmann recommends you structure your results subsection paragraphs as follows:
- Experimental purpose
- Interpretation
Each subheading may contain a combination of ( Bahadoran, 2019 ; Hofmann, 2013, pg. 62-63):
- Text: to explain about the research data
- Figures: to display the research data and to show trends or relationships, for examples using graphs or gel pictures.
- Tables: to represent a large data and exact value
Decide on the best way to present your data — in the form of text, figures or tables (Hofmann, 2013).
Data or Results?
Sometimes we get confused about how to differentiate between data and results . Data are information (facts or numbers) that you collected from your research ( Bahadoran, 2019 ).

Whereas, results are the texts presenting the meaning of your research data ( Bahadoran, 2019 ).

One mistake that some authors often make is to use text to direct the reader to find a specific table or figure without further explanation. This can confuse readers when they interpret data completely different from what the authors had in mind. So, you should briefly explain your data to make your information clear for the readers.
Common Elements in Figures and Tables
Figures and tables present information about your research data visually. The use of these visual elements is necessary so readers can summarize, compare, and interpret large data at a glance. You can use graphs or figures to compare groups or patterns. Whereas, tables are ideal to present large quantities of data and exact values.
Several components are needed to create your figures and tables. These elements are important to sort your data based on groups (or treatments). It will be easier for the readers to see the similarities and differences among the groups.
When presenting your research data in the form of figures and tables, organize your data based on the steps of the research leading you into a conclusion.
Common elements of the figures (Bahadoran, 2019):
- Figure number
- Figure title
- Figure legend (for example a brief title, experimental/statistical information, or definition of symbols).

Tables in the result section may contain several elements (Bahadoran, 2019):
- Table number
- Table title
- Row headings (for example groups)
- Column headings
- Row subheadings (for example categories or groups)
- Column subheadings (for example categories or variables)
- Footnotes (for example statistical analyses)

Tips to Write the Results Section
- Direct the reader to the research data and explain the meaning of the data.
- Avoid using a repetitive sentence structure to explain a new set of data.
- Write and highlight important findings in your results.
- Use the same order as the subheadings of the methods section.
- Match the results with the research questions from the introduction. Your results should answer your research questions.
- Be sure to mention the figures and tables in the body of your text.
- Make sure there is no mismatch between the table number or the figure number in text and in figure/tables.
- Only present data that support the significance of your study. You can provide additional data in tables and figures as supplementary material.
How to Organize the Discussion Section
It’s not enough to use figures and tables in your results section to convince your readers about the importance of your findings. You need to support your results section by providing more explanation in the discussion section about what you found.
In the discussion section, based on your findings, you defend the answers to your research questions and create arguments to support your conclusions.
Below is a list of questions to guide you when organizing the structure of your discussion section ( Viera et al ., 2018 ):
- What experiments did you conduct and what were the results?
- What do the results mean?
- What were the important results from your study?
- How did the results answer your research questions?
- Did your results support your hypothesis or reject your hypothesis?
- What are the variables or factors that might affect your results?
- What were the strengths and limitations of your study?
- What other published works support your findings?
- What other published works contradict your findings?
- What possible factors might cause your findings different from other findings?
- What is the significance of your research?
- What are new research questions to explore based on your findings?
Organizing the Discussion Section
The structure of the discussion section may be different from one paper to another, but it commonly has a beginning, middle-, and end- to the section.

One way to organize the structure of the discussion section is by dividing it into three parts (Ghasemi, 2019):
- The beginning: The first sentence of the first paragraph should state the importance and the new findings of your research. The first paragraph may also include answers to your research questions mentioned in your introduction section.
- The middle: The middle should contain the interpretations of the results to defend your answers, the strength of the study, the limitations of the study, and an update literature review that validates your findings.
- The end: The end concludes the study and the significance of your research.
Another possible way to organize the discussion section was proposed by Michael Docherty in British Medical Journal: is by using this structure ( Docherty, 1999 ):
- Discussion of important findings
- Comparison of your results with other published works
- Include the strengths and limitations of the study
- Conclusion and possible implications of your study, including the significance of your study – address why and how is it meaningful
- Future research questions based on your findings
Finally, a last option is structuring your discussion this way (Hofmann, 2013, pg. 104):
- First Paragraph: Provide an interpretation based on your key findings. Then support your interpretation with evidence.
- Secondary results
- Limitations
- Unexpected findings
- Comparisons to previous publications
- Last Paragraph: The last paragraph should provide a summarization (conclusion) along with detailing the significance, implications and potential next steps.
Remember, at the heart of the discussion section is presenting an interpretation of your major findings.
Tips to Write the Discussion Section
- Highlight the significance of your findings
- Mention how the study will fill a gap in knowledge.
- Indicate the implication of your research.
- Avoid generalizing, misinterpreting your results, drawing a conclusion with no supportive findings from your results.
Aggarwal, R., & Sahni, P. (2018). The Results Section. In Reporting and Publishing Research in the Biomedical Sciences (pp. 21-38): Springer.
Bahadoran, Z., Mirmiran, P., Zadeh-Vakili, A., Hosseinpanah, F., & Ghasemi, A. (2019). The principles of biomedical scientific writing: Results. International journal of endocrinology and metabolism, 17(2).
Bordage, G. (2001). Reasons reviewers reject and accept manuscripts: the strengths and weaknesses in medical education reports. Academic medicine, 76(9), 889-896.
Cals, J. W., & Kotz, D. (2013). Effective writing and publishing scientific papers, part VI: discussion. Journal of clinical epidemiology, 66(10), 1064.
Docherty, M., & Smith, R. (1999). The case for structuring the discussion of scientific papers: Much the same as that for structuring abstracts. In: British Medical Journal Publishing Group.
Faber, J. (2017). Writing scientific manuscripts: most common mistakes. Dental press journal of orthodontics, 22(5), 113-117.
Fletcher, R. H., & Fletcher, S. W. (2018). The discussion section. In Reporting and Publishing Research in the Biomedical Sciences (pp. 39-48): Springer.
Ghasemi, A., Bahadoran, Z., Mirmiran, P., Hosseinpanah, F., Shiva, N., & Zadeh-Vakili, A. (2019). The Principles of Biomedical Scientific Writing: Discussion. International journal of endocrinology and metabolism, 17(3).
Hofmann, A. H. (2013). Writing in the biological sciences: a comprehensive resource for scientific communication . New York: Oxford University Press.
Kotz, D., & Cals, J. W. (2013). Effective writing and publishing scientific papers, part V: results. Journal of clinical epidemiology, 66(9), 945.
Mack, C. (2014). How to Write a Good Scientific Paper: Structure and Organization. Journal of Micro/ Nanolithography, MEMS, and MOEMS, 13. doi:10.1117/1.JMM.13.4.040101
Moore, A. (2016). What's in a Discussion section? Exploiting 2‐dimensionality in the online world…. Bioessays, 38(12), 1185-1185.
Peat, J., Elliott, E., Baur, L., & Keena, V. (2013). Scientific writing: easy when you know how: John Wiley & Sons.
Sandercock, P. M. L. (2012). How to write and publish a scientific article. Canadian Society of Forensic Science Journal, 45(1), 1-5.
Teo, E. K. (2016). Effective Medical Writing: The Write Way to Get Published. Singapore Medical Journal, 57(9), 523-523. doi:10.11622/smedj.2016156
Van Way III, C. W. (2007). Writing a scientific paper. Nutrition in Clinical Practice, 22(6), 636-640.
Vieira, R. F., Lima, R. C. d., & Mizubuti, E. S. G. (2019). How to write the discussion section of a scientific article. Acta Scientiarum. Agronomy, 41.
Related Articles

A quality research paper has both the qualities of in-depth research and good writing (Bordage, 200...

How to Survive and Complete a Thesis or a Dissertation
Writing a thesis or a dissertation can be a challenging process for many graduate students. There ar...

12 Ways to Dramatically Improve your Research Manuscript Title and Abstract
The first thing a person doing literary research will see is a research publication title. After tha...

15 Laboratory Notebook Tips to Help with your Research Manuscript
Your lab notebook is a foundation to your research manuscript. It serves almost as a rudimentary dra...
Join our list to receive promos and articles.
- Competent Cells
- Lab Startup
- Z')" data-type="collection" title="Products A->Z" target="_self" href="/collection/products-a-to-z">Products A->Z
- GoldBio Resources
- GoldBio Sales Team
- GoldBio Distributors
- Duchefa Direct
- Sign up for Promos
- Terms & Conditions
- ISO Certification
- Agarose Resins
- Antibiotics & Selection
- Biochemical Reagents
- Bioluminescence
- Buffers & Reagents
- Cell Culture
- Cloning & Induction
- Competent Cells and Transformation
- Detergents & Membrane Agents
- DNA Amplification
- Enzymes, Inhibitors & Substrates
- Growth Factors and Cytokines
- Lab Tools & Accessories
- Plant Research and Reagents
- Protein Research & Analysis
- Protein Expression & Purification
- Reducing Agents
- Affiliate Program

- UNITED STATES
- 台灣 (TAIWAN)
- TÜRKIYE (TURKEY)
- Academic Editing Services
- - Research Paper
- - Journal Manuscript
- - Dissertation
- - College & University Assignments
- Admissions Editing Services
- - Application Essay
- - Personal Statement
- - Recommendation Letter
- - Cover Letter
- - CV/Resume
- Business Editing Services
- - Business Documents
- - Report & Brochure
- - Website & Blog
- Writer Editing Services
- - Script & Screenplay
- Our Editors
- Client Reviews
- Editing & Proofreading Prices
- Wordvice Points
- Partner Discount
- Plagiarism Checker
- APA Citation Generator
- MLA Citation Generator
- Chicago Citation Generator
- Vancouver Citation Generator
- - APA Style
- - MLA Style
- - Chicago Style
- - Vancouver Style
- Writing & Editing Guide
- Academic Resources
- Admissions Resources
How to Write the Results/Findings Section in Research
What is the research paper Results section and what does it do?
The Results section of a scientific research paper represents the core findings of a study derived from the methods applied to gather and analyze information. It presents these findings in a logical sequence without bias or interpretation from the author, setting up the reader for later interpretation and evaluation in the Discussion section. A major purpose of the Results section is to break down the data into sentences that show its significance to the research question(s).
The Results section appears third in the section sequence in most scientific papers. It follows the presentation of the Methods and Materials and is presented before the Discussion section —although the Results and Discussion are presented together in many journals. This section answers the basic question “What did you find in your research?”
What is included in the Results section?
The Results section should include the findings of your study and ONLY the findings of your study. The findings include:
- Data presented in tables, charts, graphs, and other figures (may be placed into the text or on separate pages at the end of the manuscript)
- A contextual analysis of this data explaining its meaning in sentence form
- All data that corresponds to the central research question(s)
- All secondary findings (secondary outcomes, subgroup analyses, etc.)
If the scope of the study is broad, or if you studied a variety of variables, or if the methodology used yields a wide range of different results, the author should present only those results that are most relevant to the research question stated in the Introduction section .
As a general rule, any information that does not present the direct findings or outcome of the study should be left out of this section. Unless the journal requests that authors combine the Results and Discussion sections, explanations and interpretations should be omitted from the Results.
How are the results organized?
The best way to organize your Results section is “logically.” One logical and clear method of organizing research results is to provide them alongside the research questions—within each research question, present the type of data that addresses that research question.
Let’s look at an example. Your research question is based on a survey among patients who were treated at a hospital and received postoperative care. Let’s say your first research question is:

“What do hospital patients over age 55 think about postoperative care?”
This can actually be represented as a heading within your Results section, though it might be presented as a statement rather than a question:
Attitudes towards postoperative care in patients over the age of 55
Now present the results that address this specific research question first. In this case, perhaps a table illustrating data from a survey. Likert items can be included in this example. Tables can also present standard deviations, probabilities, correlation matrices, etc.
Following this, present a content analysis, in words, of one end of the spectrum of the survey or data table. In our example case, start with the POSITIVE survey responses regarding postoperative care, using descriptive phrases. For example:
“Sixty-five percent of patients over 55 responded positively to the question “ Are you satisfied with your hospital’s postoperative care ?” (Fig. 2)
Include other results such as subcategory analyses. The amount of textual description used will depend on how much interpretation of tables and figures is necessary and how many examples the reader needs in order to understand the significance of your research findings.
Next, present a content analysis of another part of the spectrum of the same research question, perhaps the NEGATIVE or NEUTRAL responses to the survey. For instance:
“As Figure 1 shows, 15 out of 60 patients in Group A responded negatively to Question 2.”
After you have assessed the data in one figure and explained it sufficiently, move on to your next research question. For example:
“How does patient satisfaction correspond to in-hospital improvements made to postoperative care?”

This kind of data may be presented through a figure or set of figures (for instance, a paired T-test table).
Explain the data you present, here in a table, with a concise content analysis:
“The p-value for the comparison between the before and after groups of patients was .03% (Fig. 2), indicating that the greater the dissatisfaction among patients, the more frequent the improvements that were made to postoperative care.”
Let’s examine another example of a Results section from a study on plant tolerance to heavy metal stress . In the Introduction section, the aims of the study are presented as “determining the physiological and morphological responses of Allium cepa L. towards increased cadmium toxicity” and “evaluating its potential to accumulate the metal and its associated environmental consequences.” The Results section presents data showing how these aims are achieved in tables alongside a content analysis, beginning with an overview of the findings:
“Cadmium caused inhibition of root and leave elongation, with increasing effects at higher exposure doses (Fig. 1a-c).”
The figure containing this data is cited in parentheses. Note that this author has combined three graphs into one single figure. Separating the data into separate graphs focusing on specific aspects makes it easier for the reader to assess the findings, and consolidating this information into one figure saves space and makes it easy to locate the most relevant results.

Following this overall summary, the relevant data in the tables is broken down into greater detail in text form in the Results section.
- “Results on the bio-accumulation of cadmium were found to be the highest (17.5 mg kgG1) in the bulb, when the concentration of cadmium in the solution was 1×10G2 M and lowest (0.11 mg kgG1) in the leaves when the concentration was 1×10G3 M.”
Captioning and Referencing Tables and Figures
Tables and figures are central components of your Results section and you need to carefully think about the most effective way to use graphs and tables to present your findings . Therefore, it is crucial to know how to write strong figure captions and to refer to them within the text of the Results section.
The most important advice one can give here as well as throughout the paper is to check the requirements and standards of the journal to which you are submitting your work. Every journal has its own design and layout standards, which you can find in the author instructions on the target journal’s website. Perusing a journal’s published articles will also give you an idea of the proper number, size, and complexity of your figures.
Regardless of which format you use, the figures should be placed in the order they are referenced in the Results section and be as clear and easy to understand as possible. If there are multiple variables being considered (within one or more research questions), it can be a good idea to split these up into separate figures. Subsequently, these can be referenced and analyzed under separate headings and paragraphs in the text.
To create a caption, consider the research question being asked and change it into a phrase. For instance, if one question is “Which color did participants choose?”, the caption might be “Color choice by participant group.” Or in our last research paper example, where the question was “What is the concentration of cadmium in different parts of the onion after 14 days?” the caption reads:
“Fig. 1(a-c): Mean concentration of Cd determined in (a) bulbs, (b) leaves, and (c) roots of onions after a 14-day period.”
Steps for Composing the Results Section
Because each study is unique, there is no one-size-fits-all approach when it comes to designing a strategy for structuring and writing the section of a research paper where findings are presented. The content and layout of this section will be determined by the specific area of research, the design of the study and its particular methodologies, and the guidelines of the target journal and its editors. However, the following steps can be used to compose the results of most scientific research studies and are essential for researchers who are new to preparing a manuscript for publication or who need a reminder of how to construct the Results section.
Step 1 : Consult the guidelines or instructions that the target journal or publisher provides authors and read research papers it has published, especially those with similar topics, methods, or results to your study.
- The guidelines will generally outline specific requirements for the results or findings section, and the published articles will provide sound examples of successful approaches.
- Note length limitations on restrictions on content. For instance, while many journals require the Results and Discussion sections to be separate, others do not—qualitative research papers often include results and interpretations in the same section (“Results and Discussion”).
- Reading the aims and scope in the journal’s “ guide for authors ” section and understanding the interests of its readers will be invaluable in preparing to write the Results section.
Step 2 : Consider your research results in relation to the journal’s requirements and catalogue your results.
- Focus on experimental results and other findings that are especially relevant to your research questions and objectives and include them even if they are unexpected or do not support your ideas and hypotheses.
- Catalogue your findings—use subheadings to streamline and clarify your report. This will help you avoid excessive and peripheral details as you write and also help your reader understand and remember your findings. Create appendices that might interest specialists but prove too long or distracting for other readers.
- Decide how you will structure of your results. You might match the order of the research questions and hypotheses to your results, or you could arrange them according to the order presented in the Methods section. A chronological order or even a hierarchy of importance or meaningful grouping of main themes or categories might prove effective. Consider your audience, evidence, and most importantly, the objectives of your research when choosing a structure for presenting your findings.
Step 3 : Design figures and tables to present and illustrate your data.
- Tables and figures should be numbered according to the order in which they are mentioned in the main text of the paper.
- Information in figures should be relatively self-explanatory (with the aid of captions), and their design should include all definitions and other information necessary for readers to understand the findings without reading all of the text.
- Use tables and figures as a focal point to tell a clear and informative story about your research and avoid repeating information. But remember that while figures clarify and enhance the text, they cannot replace it.
Step 4 : Draft your Results section using the findings and figures you have organized.
- The goal is to communicate this complex information as clearly and precisely as possible; precise and compact phrases and sentences are most effective.
- In the opening paragraph of this section, restate your research questions or aims to focus the reader’s attention to what the results are trying to show. It is also a good idea to summarize key findings at the end of this section to create a logical transition to the interpretation and discussion that follows.
- Try to write in the past tense and the active voice to relay the findings since the research has already been done and the agent is usually clear. This will ensure that your explanations are also clear and logical.
- Make sure that any specialized terminology or abbreviation you have used here has been defined and clarified in the Introduction section .
Step 5 : Review your draft; edit and revise until it reports results exactly as you would like to have them reported to your readers.
- Double-check the accuracy and consistency of all the data, as well as all of the visual elements included.
- Read your draft aloud to catch language errors (grammar, spelling, and mechanics), awkward phrases, and missing transitions.
- Ensure that your results are presented in the best order to focus on objectives and prepare readers for interpretations, valuations, and recommendations in the Discussion section . Look back over the paper’s Introduction and background while anticipating the Discussion and Conclusion sections to ensure that the presentation of your results is consistent and effective.
- Consider seeking additional guidance on your paper. Find additional readers to look over your Results section and see if it can be improved in any way. Peers, professors, or qualified experts can provide valuable insights.
One excellent option is to use a professional English proofreading and editing service such as Wordvice, including our paper editing service . With hundreds of qualified editors from dozens of scientific fields, Wordvice has helped thousands of authors revise their manuscripts and get accepted into their target journals. Read more about the proofreading and editing process before proceeding with getting academic editing services and manuscript editing services for your manuscript.
As the representation of your study’s data output, the Results section presents the core information in your research paper. By writing with clarity and conciseness and by highlighting and explaining the crucial findings of their study, authors increase the impact and effectiveness of their research manuscripts.
For more articles and videos on writing your research manuscript, visit Wordvice’s Resources page.
Wordvice Resources
- How to Write a Research Paper Introduction
- Which Verb Tenses to Use in a Research Paper
- How to Write an Abstract for a Research Paper
- How to Write a Research Paper Title
- Useful Phrases for Academic Writing
- Common Transition Terms in Academic Papers
- Active and Passive Voice in Research Papers
- 100+ Verbs That Will Make Your Research Writing Amazing
- Tips for Paraphrasing in Research Papers
Organizing Academic Research Papers: 7. The Results
- Purpose of Guide
- Design Flaws to Avoid
- Glossary of Research Terms
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Choosing a Title
- Making an Outline
- Paragraph Development
- Executive Summary
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tertiary Sources
- What Is Scholarly vs. Popular?
- Qualitative Methods
- Quantitative Methods
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Annotated Bibliography
- Dealing with Nervousness
- Using Visual Aids
- Grading Someone Else's Paper
- How to Manage Group Projects
- Multiple Book Review Essay
- Reviewing Collected Essays
- About Informed Consent
- Writing Field Notes
- Writing a Policy Memo
- Writing a Research Proposal
- Acknowledgements
The results section of the research paper is where you report the findings of your study based upon the information gathered as a result of the methodology [or methodologies] you applied. The results section should simply state the findings, without bias or interpretation, and arranged in a logical sequence. The results section should always be written in the past tense. A section describing results [a.k.a., "findings"] is particularly necessary if your paper includes data generated from your own research.
Importance of a Good Results Section
When formulating the results section, it's important to remember that the results of a study do not prove anything . Research results can only confirm or reject the research problem underpinning your study. However, the act of articulating the results helps you to understand the problem from within, to break it into pieces, and to view the research problem from various perspectives.
The page length of this section is set by the amount and types of data to be reported . Be concise, using non-textual elements, such as figures and tables, if appropriate, to present results more effectively. In deciding what data to describe in your results section, you must clearly distinguish material that would normally be included in a research paper from any raw data or other material that could be included as an appendix. In general, raw data should not be included in the main text of your paper unless requested to do so by your professor.
Avoid providing data that is not critical to answering the research question . The background information you described in the introduction section should provide the reader with any additional context or explanation needed to understand the results. A good rule is to always re-read the background section of your paper after you have written up your results to ensure that the reader has enough context to understand the results [and, later, how you interpreted the results in the discussion section of your paper].
Bates College; Burton, Neil et al. Doing Your Education Research Project . Los Angeles, CA: SAGE, 2008; Results . The Structure, Format, Content, and Style of a Journal-Style Scientific Paper. Department of Biology. Bates College.
Structure and Writing Style
I. Structure and Approach
For most research paper formats, there are two ways of presenting and organizing the results .
- Present the results followed by a short explanation of the findings . For example, you may have noticed an unusual correlation between two variables during the analysis of your findings. It is correct to point this out in the results section. However, speculating as to why this correlation exists, and offering a hypothesis about what may be happening, belongs in the discussion section of your paper.
- Present a section and then discuss it, before presenting the next section then discussing it, and so on . This is more common in longer papers because it helps the reader to better understand each finding. In this model, it can be helpful to provide a brief conclusion in the results section that ties each of the findings together and links to the discussion.
NOTE: The discussion section should generally follow the same format chosen in presenting and organizing the results.
II. Content
In general, the content of your results section should include the following elements:
- An introductory context for understanding the results by restating the research problem that underpins the purpose of your study.
- A summary of your key findings arranged in a logical sequence that generally follows your methodology section.
- Inclusion of non-textual elements, such as, figures, charts, photos, maps, tables, etc. to further illustrate the findings, if appropriate.
- In the text, a systematic description of your results, highlighting for the reader observations that are most relevant to the topic under investigation [remember that not all results that emerge from the methodology that you used to gather the data may be relevant].
- Use of the past tense when refering to your results.
- The page length of your results section is guided by the amount and types of data to be reported. However, focus only on findings that are important and related to addressing the research problem.
Using Non-textual Elements
- Either place figures, tables, charts, etc. within the text of the result, or include them in the back of the report--do one or the other but never do both.
- In the text, refer to each non-textual element in numbered order [e.g., Table 1, Table 2; Chart 1, Chart 2; Map 1, Map 2].
- If you place non-textual elements at the end of the report, make sure they are clearly distinguished from any attached appendix materials, such as raw data.
- Regardless of placement, each non-textual element must be numbered consecutively and complete with caption [caption goes under the figure, table, chart, etc.]
- Each non-textual element must be titled, numbered consecutively, and complete with a heading [title with description goes above the figure, table, chart, etc.].
- In proofreading your results section, be sure that each non-textual element is sufficiently complete so that it could stand on its own, separate from the text.
III. Problems to Avoid
When writing the results section, avoid doing the following :
- Discussing or interpreting your results . Save all this for the next section of your paper, although where appropriate, you should compare or contrast specific results to those found in other studies [e.g., "Similar to Smith [1990], one of the findings of this study is the strong correlation between motivation and academic achievement...."].
- Reporting background information or attempting to explain your findings ; this should have been done in your Introduction section, but don't panic! Often the results of a study point to the need to provide additional background information or to explain the topic further, so don't think you did something wrong. Revise your introduction as needed.
- Ignoring negative results . If some of your results fail to support your hypothesis, do not ignore them. Document them, then state in your discussion section why you believe a negative result emerged from your study. Note that negative results, and how you handle them, often provides you with the opportunity to write a more engaging discussion section, therefore, don't be afraid to highlight them.
- Including raw data or intermediate calculations . Ask your professor if you need to include any raw data generated by your study, such as transcripts from interviews or data files. If raw data is to be included, place it in an appendix or set of appendices that are referred to in the text.
- Be as factual and concise as possible in reporting your findings . Do not use phrases that are vague or non-specific, such as, "appeared to be greater or lesser than..." or "demonstrates promising trends that...."
- Presenting the same data or repeating the same information more than once . If you feel the need to highlight something, you will have a chance to do that in the discussion section.
- Confusing figures with tables . Be sure to properly label any non-textual elements in your paper. If you are not sure, look up the term in a dictionary.
Burton, Neil et al. Doing Your Education Research Project . Los Angeles, CA: SAGE, 2008; Caprette, David R. Writing Research Papers . Experimental Biosciences Resources. Rice University; Hancock, Dawson R. and Bob Algozzine. Doing Case Study Research: A Practical Guide for Beginning Researchers . 2nd ed. New York: Teachers College Press, 2011; Introduction to Nursing Research: Reporting Research Findings. Nursing Research: Open Access Nursing Research and Review Articles. (January 4, 2012); Reporting Research Findings. Wilder Research, in partnership with the Minnesota Department of Human Services. (February 2009); Results . The Structure, Format, Content, and Style of a Journal-Style Scientific Paper. Department of Biology. Bates College; Schafer, Mickey S. Writing the Results . Thesis Writing in the Sciences. Course Syllabus. University of Florida.
Writing Tip
Why Don't I Just Combine the Results Section with the Discussion Section?
It's not unusual to find articles in social science journals where the author(s) have combined a description of the findings from the study with a discussion about their implications. You could do this. However, if you are inexperienced writing research papers, consider creating two sections for each element in your paper as a way to better organize your thoughts and, by extension, your paper. Think of the results section as the place where you report what your study found; think of the discussion section as the place where you interpret your data and answer the "so what?" question. As you become more skilled writing research papers, you may want to meld the results of your study with a discussion of its implications.
- << Previous: Quantitative Methods
- Next: Using Non-Textual Elements >>
- Last Updated: Jul 18, 2023 11:58 AM
- URL: https://library.sacredheart.edu/c.php?g=29803
- QuickSearch
- Library Catalog
- Databases A-Z
- Publication Finder
- Course Reserves
- Citation Linker
- Digital Commons
- Our Website
Research Support
- Ask a Librarian
- Appointments
- Interlibrary Loan (ILL)
- Research Guides
- Databases by Subject
- Citation Help
Using the Library
- Reserve a Group Study Room
- Renew Books
- Honors Study Rooms
- Off-Campus Access
- Library Policies
- Library Technology
User Information
- Grad Students
- Online Students
- COVID-19 Updates
- Staff Directory
- News & Announcements
- Library Newsletter
My Accounts
- Interlibrary Loan
- Staff Site Login
FIND US ON
- Privacy Policy
Home » Research Report – Example, Writing Guide and Types
Research Report – Example, Writing Guide and Types
Table of Contents

Research Report
Definition:
Research Report is a written document that presents the results of a research project or study, including the research question, methodology, results, and conclusions, in a clear and objective manner.
The purpose of a research report is to communicate the findings of the research to the intended audience, which could be other researchers, stakeholders, or the general public.
Components of Research Report
Components of Research Report are as follows:
Introduction
The introduction sets the stage for the research report and provides a brief overview of the research question or problem being investigated. It should include a clear statement of the purpose of the study and its significance or relevance to the field of research. It may also provide background information or a literature review to help contextualize the research.
Literature Review
The literature review provides a critical analysis and synthesis of the existing research and scholarship relevant to the research question or problem. It should identify the gaps, inconsistencies, and contradictions in the literature and show how the current study addresses these issues. The literature review also establishes the theoretical framework or conceptual model that guides the research.
Methodology
The methodology section describes the research design, methods, and procedures used to collect and analyze data. It should include information on the sample or participants, data collection instruments, data collection procedures, and data analysis techniques. The methodology should be clear and detailed enough to allow other researchers to replicate the study.
The results section presents the findings of the study in a clear and objective manner. It should provide a detailed description of the data and statistics used to answer the research question or test the hypothesis. Tables, graphs, and figures may be included to help visualize the data and illustrate the key findings.
The discussion section interprets the results of the study and explains their significance or relevance to the research question or problem. It should also compare the current findings with those of previous studies and identify the implications for future research or practice. The discussion should be based on the results presented in the previous section and should avoid speculation or unfounded conclusions.
The conclusion summarizes the key findings of the study and restates the main argument or thesis presented in the introduction. It should also provide a brief overview of the contributions of the study to the field of research and the implications for practice or policy.
The references section lists all the sources cited in the research report, following a specific citation style, such as APA or MLA.
The appendices section includes any additional material, such as data tables, figures, or instruments used in the study, that could not be included in the main text due to space limitations.
Types of Research Report
Types of Research Report are as follows:
Thesis is a type of research report. A thesis is a long-form research document that presents the findings and conclusions of an original research study conducted by a student as part of a graduate or postgraduate program. It is typically written by a student pursuing a higher degree, such as a Master’s or Doctoral degree, although it can also be written by researchers or scholars in other fields.
Research Paper
Research paper is a type of research report. A research paper is a document that presents the results of a research study or investigation. Research papers can be written in a variety of fields, including science, social science, humanities, and business. They typically follow a standard format that includes an introduction, literature review, methodology, results, discussion, and conclusion sections.
Technical Report
A technical report is a detailed report that provides information about a specific technical or scientific problem or project. Technical reports are often used in engineering, science, and other technical fields to document research and development work.
Progress Report
A progress report provides an update on the progress of a research project or program over a specific period of time. Progress reports are typically used to communicate the status of a project to stakeholders, funders, or project managers.
Feasibility Report
A feasibility report assesses the feasibility of a proposed project or plan, providing an analysis of the potential risks, benefits, and costs associated with the project. Feasibility reports are often used in business, engineering, and other fields to determine the viability of a project before it is undertaken.
Field Report
A field report documents observations and findings from fieldwork, which is research conducted in the natural environment or setting. Field reports are often used in anthropology, ecology, and other social and natural sciences.
Experimental Report
An experimental report documents the results of a scientific experiment, including the hypothesis, methods, results, and conclusions. Experimental reports are often used in biology, chemistry, and other sciences to communicate the results of laboratory experiments.
Case Study Report
A case study report provides an in-depth analysis of a specific case or situation, often used in psychology, social work, and other fields to document and understand complex cases or phenomena.
Literature Review Report
A literature review report synthesizes and summarizes existing research on a specific topic, providing an overview of the current state of knowledge on the subject. Literature review reports are often used in social sciences, education, and other fields to identify gaps in the literature and guide future research.
Research Report Example
Following is a Research Report Example sample for Students:
Title: The Impact of Social Media on Academic Performance among High School Students
This study aims to investigate the relationship between social media use and academic performance among high school students. The study utilized a quantitative research design, which involved a survey questionnaire administered to a sample of 200 high school students. The findings indicate that there is a negative correlation between social media use and academic performance, suggesting that excessive social media use can lead to poor academic performance among high school students. The results of this study have important implications for educators, parents, and policymakers, as they highlight the need for strategies that can help students balance their social media use and academic responsibilities.
Introduction:
Social media has become an integral part of the lives of high school students. With the widespread use of social media platforms such as Facebook, Twitter, Instagram, and Snapchat, students can connect with friends, share photos and videos, and engage in discussions on a range of topics. While social media offers many benefits, concerns have been raised about its impact on academic performance. Many studies have found a negative correlation between social media use and academic performance among high school students (Kirschner & Karpinski, 2010; Paul, Baker, & Cochran, 2012).
Given the growing importance of social media in the lives of high school students, it is important to investigate its impact on academic performance. This study aims to address this gap by examining the relationship between social media use and academic performance among high school students.
Methodology:
The study utilized a quantitative research design, which involved a survey questionnaire administered to a sample of 200 high school students. The questionnaire was developed based on previous studies and was designed to measure the frequency and duration of social media use, as well as academic performance.
The participants were selected using a convenience sampling technique, and the survey questionnaire was distributed in the classroom during regular school hours. The data collected were analyzed using descriptive statistics and correlation analysis.
The findings indicate that the majority of high school students use social media platforms on a daily basis, with Facebook being the most popular platform. The results also show a negative correlation between social media use and academic performance, suggesting that excessive social media use can lead to poor academic performance among high school students.
Discussion:
The results of this study have important implications for educators, parents, and policymakers. The negative correlation between social media use and academic performance suggests that strategies should be put in place to help students balance their social media use and academic responsibilities. For example, educators could incorporate social media into their teaching strategies to engage students and enhance learning. Parents could limit their children’s social media use and encourage them to prioritize their academic responsibilities. Policymakers could develop guidelines and policies to regulate social media use among high school students.
Conclusion:
In conclusion, this study provides evidence of the negative impact of social media on academic performance among high school students. The findings highlight the need for strategies that can help students balance their social media use and academic responsibilities. Further research is needed to explore the specific mechanisms by which social media use affects academic performance and to develop effective strategies for addressing this issue.
Limitations:
One limitation of this study is the use of convenience sampling, which limits the generalizability of the findings to other populations. Future studies should use random sampling techniques to increase the representativeness of the sample. Another limitation is the use of self-reported measures, which may be subject to social desirability bias. Future studies could use objective measures of social media use and academic performance, such as tracking software and school records.
Implications:
The findings of this study have important implications for educators, parents, and policymakers. Educators could incorporate social media into their teaching strategies to engage students and enhance learning. For example, teachers could use social media platforms to share relevant educational resources and facilitate online discussions. Parents could limit their children’s social media use and encourage them to prioritize their academic responsibilities. They could also engage in open communication with their children to understand their social media use and its impact on their academic performance. Policymakers could develop guidelines and policies to regulate social media use among high school students. For example, schools could implement social media policies that restrict access during class time and encourage responsible use.
References:
- Kirschner, P. A., & Karpinski, A. C. (2010). Facebook® and academic performance. Computers in Human Behavior, 26(6), 1237-1245.
- Paul, J. A., Baker, H. M., & Cochran, J. D. (2012). Effect of online social networking on student academic performance. Journal of the Research Center for Educational Technology, 8(1), 1-19.
- Pantic, I. (2014). Online social networking and mental health. Cyberpsychology, Behavior, and Social Networking, 17(10), 652-657.
- Rosen, L. D., Carrier, L. M., & Cheever, N. A. (2013). Facebook and texting made me do it: Media-induced task-switching while studying. Computers in Human Behavior, 29(3), 948-958.
Note*: Above mention, Example is just a sample for the students’ guide. Do not directly copy and paste as your College or University assignment. Kindly do some research and Write your own.
Applications of Research Report
Research reports have many applications, including:
- Communicating research findings: The primary application of a research report is to communicate the results of a study to other researchers, stakeholders, or the general public. The report serves as a way to share new knowledge, insights, and discoveries with others in the field.
- Informing policy and practice : Research reports can inform policy and practice by providing evidence-based recommendations for decision-makers. For example, a research report on the effectiveness of a new drug could inform regulatory agencies in their decision-making process.
- Supporting further research: Research reports can provide a foundation for further research in a particular area. Other researchers may use the findings and methodology of a report to develop new research questions or to build on existing research.
- Evaluating programs and interventions : Research reports can be used to evaluate the effectiveness of programs and interventions in achieving their intended outcomes. For example, a research report on a new educational program could provide evidence of its impact on student performance.
- Demonstrating impact : Research reports can be used to demonstrate the impact of research funding or to evaluate the success of research projects. By presenting the findings and outcomes of a study, research reports can show the value of research to funders and stakeholders.
- Enhancing professional development : Research reports can be used to enhance professional development by providing a source of information and learning for researchers and practitioners in a particular field. For example, a research report on a new teaching methodology could provide insights and ideas for educators to incorporate into their own practice.
How to write Research Report
Here are some steps you can follow to write a research report:
- Identify the research question: The first step in writing a research report is to identify your research question. This will help you focus your research and organize your findings.
- Conduct research : Once you have identified your research question, you will need to conduct research to gather relevant data and information. This can involve conducting experiments, reviewing literature, or analyzing data.
- Organize your findings: Once you have gathered all of your data, you will need to organize your findings in a way that is clear and understandable. This can involve creating tables, graphs, or charts to illustrate your results.
- Write the report: Once you have organized your findings, you can begin writing the report. Start with an introduction that provides background information and explains the purpose of your research. Next, provide a detailed description of your research methods and findings. Finally, summarize your results and draw conclusions based on your findings.
- Proofread and edit: After you have written your report, be sure to proofread and edit it carefully. Check for grammar and spelling errors, and make sure that your report is well-organized and easy to read.
- Include a reference list: Be sure to include a list of references that you used in your research. This will give credit to your sources and allow readers to further explore the topic if they choose.
- Format your report: Finally, format your report according to the guidelines provided by your instructor or organization. This may include formatting requirements for headings, margins, fonts, and spacing.
Purpose of Research Report
The purpose of a research report is to communicate the results of a research study to a specific audience, such as peers in the same field, stakeholders, or the general public. The report provides a detailed description of the research methods, findings, and conclusions.
Some common purposes of a research report include:
- Sharing knowledge: A research report allows researchers to share their findings and knowledge with others in their field. This helps to advance the field and improve the understanding of a particular topic.
- Identifying trends: A research report can identify trends and patterns in data, which can help guide future research and inform decision-making.
- Addressing problems: A research report can provide insights into problems or issues and suggest solutions or recommendations for addressing them.
- Evaluating programs or interventions : A research report can evaluate the effectiveness of programs or interventions, which can inform decision-making about whether to continue, modify, or discontinue them.
- Meeting regulatory requirements: In some fields, research reports are required to meet regulatory requirements, such as in the case of drug trials or environmental impact studies.
When to Write Research Report
A research report should be written after completing the research study. This includes collecting data, analyzing the results, and drawing conclusions based on the findings. Once the research is complete, the report should be written in a timely manner while the information is still fresh in the researcher’s mind.
In academic settings, research reports are often required as part of coursework or as part of a thesis or dissertation. In this case, the report should be written according to the guidelines provided by the instructor or institution.
In other settings, such as in industry or government, research reports may be required to inform decision-making or to comply with regulatory requirements. In these cases, the report should be written as soon as possible after the research is completed in order to inform decision-making in a timely manner.
Overall, the timing of when to write a research report depends on the purpose of the research, the expectations of the audience, and any regulatory requirements that need to be met. However, it is important to complete the report in a timely manner while the information is still fresh in the researcher’s mind.
Characteristics of Research Report
There are several characteristics of a research report that distinguish it from other types of writing. These characteristics include:
- Objective: A research report should be written in an objective and unbiased manner. It should present the facts and findings of the research study without any personal opinions or biases.
- Systematic: A research report should be written in a systematic manner. It should follow a clear and logical structure, and the information should be presented in a way that is easy to understand and follow.
- Detailed: A research report should be detailed and comprehensive. It should provide a thorough description of the research methods, results, and conclusions.
- Accurate : A research report should be accurate and based on sound research methods. The findings and conclusions should be supported by data and evidence.
- Organized: A research report should be well-organized. It should include headings and subheadings to help the reader navigate the report and understand the main points.
- Clear and concise: A research report should be written in clear and concise language. The information should be presented in a way that is easy to understand, and unnecessary jargon should be avoided.
- Citations and references: A research report should include citations and references to support the findings and conclusions. This helps to give credit to other researchers and to provide readers with the opportunity to further explore the topic.
Advantages of Research Report
Research reports have several advantages, including:
- Communicating research findings: Research reports allow researchers to communicate their findings to a wider audience, including other researchers, stakeholders, and the general public. This helps to disseminate knowledge and advance the understanding of a particular topic.
- Providing evidence for decision-making : Research reports can provide evidence to inform decision-making, such as in the case of policy-making, program planning, or product development. The findings and conclusions can help guide decisions and improve outcomes.
- Supporting further research: Research reports can provide a foundation for further research on a particular topic. Other researchers can build on the findings and conclusions of the report, which can lead to further discoveries and advancements in the field.
- Demonstrating expertise: Research reports can demonstrate the expertise of the researchers and their ability to conduct rigorous and high-quality research. This can be important for securing funding, promotions, and other professional opportunities.
- Meeting regulatory requirements: In some fields, research reports are required to meet regulatory requirements, such as in the case of drug trials or environmental impact studies. Producing a high-quality research report can help ensure compliance with these requirements.
Limitations of Research Report
Despite their advantages, research reports also have some limitations, including:
- Time-consuming: Conducting research and writing a report can be a time-consuming process, particularly for large-scale studies. This can limit the frequency and speed of producing research reports.
- Expensive: Conducting research and producing a report can be expensive, particularly for studies that require specialized equipment, personnel, or data. This can limit the scope and feasibility of some research studies.
- Limited generalizability: Research studies often focus on a specific population or context, which can limit the generalizability of the findings to other populations or contexts.
- Potential bias : Researchers may have biases or conflicts of interest that can influence the findings and conclusions of the research study. Additionally, participants may also have biases or may not be representative of the larger population, which can limit the validity and reliability of the findings.
- Accessibility: Research reports may be written in technical or academic language, which can limit their accessibility to a wider audience. Additionally, some research may be behind paywalls or require specialized access, which can limit the ability of others to read and use the findings.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Assignment – Types, Examples and Writing Guide

Tables in Research Paper – Types, Creating Guide...

Dissertation – Format, Example and Template

Background of The Study – Examples and Writing...

Dissertation vs Thesis – Key Differences

Research Results Section – Writing Guide and...
An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- PLoS Comput Biol
- v.10(1); 2014 Jan
Ten Simple Rules for Writing Research Papers
Weixiong zhang.
Department of Computer Science and Engineering, Department of Genetics, Washington University in St. Louis, St. Louis, Missouri, United States of America
The importance of writing well can never be overstated for a successful professional career, and the ability to write solid papers is an essential trait of a productive researcher. Writing and publishing a paper has its own life cycle; properly following a course of action and avoiding missteps can be vital to the overall success not only of a paper but of the underlying research as well. Here, we offer ten simple rules for writing and publishing research papers.
As a caveat, this essay is not about the mechanics of composing a paper, much of which has been covered elsewhere, e.g., [1] , [2] . Rather, it is about the principles and attitude that can help guide the process of writing in particular and research in general. In this regard, some of the discussion will complement, extend, and refine some advice given in early articles of this Ten Simple Rules series of PLOS Computational Biology [3] – [8] .
Rule 1: Make It a Driving Force
Never separate writing a paper from the underlying research. After all, writing and research are integral parts of the overall enterprise. Therefore, design a project with an ultimate paper firmly in mind. Include an outline of the paper in the initial project design documents to help form the research objectives, determine the logical flow of the experiments, and organize the materials and data to be used. Furthermore, use writing as a tool to reassess the overall project, reevaluate the logic of the experiments, and examine the validity of the results during the research. As a result, the overall research may need to be adjusted, the project design may be revised, new methods may be devised, and new data may be collected. The process of research and writing may be repeated if necessary.
Rule 2: Less Is More
It is often the case that more than one hypothesis or objective may be tackled in one project. It is also not uncommon that the data and results gathered for one objective can serve additional purposes. A decision on having one or more papers needs to be made, and the decision will be affected by various factors. Regardless of the validity of these factors, the overriding consideration must be the potential impact that the paper may have on the research subject and field. Therefore, the significance, completeness, and coherence of the results presented as a whole should be the principal guide for selecting the story to tell, the hypothesis to focus upon, and materials to include in the paper, as well as the yardstick for measuring the quality of the paper. By this metric, less is more , i.e., fewer but more significant papers serve both the research community and one's career better than more papers of less significance.
Rule 3: Pick the Right Audience
Deciding on an angle of the story to focus upon is the next hurdle to jump at the initial stage of the writing. The results from a computational study of a biological problem can often be presented to biologists, computational scientists, or both; deciding what story to tell and from what angle to pitch the main idea is important. This issue translates to choosing a target audience, as well as an appropriate journal, to cast the main messages to. This is critical for determining the organization of the paper and the level of detail of the story, so as to write the paper with the audience in mind. Indeed, writing a paper for biologists in general is different from writing for specialists in computational biology.
Rule 4: Be Logical
The foundation of “lively” writing for smooth reading is a sound and clear logic underlying the story of the paper. Although experiments may be carried out independently, the result from one experiment may form premises and/or provide supporting data for the next experiment. The experiments and results, therefore, must be presented in a logical order. In order to make the writing an easy process to follow, this logical flow should be determined before any other writing strategy or tactic is exercised. This logical order can also help you avoid discussing the same issue or presenting the same argument in multiple places in the paper, which may dilute the readers' attention.
An effective tactic to help develop a sound logical flow is to imaginatively create a set of figures and tables, which will ultimately be developed from experimental results, and order them in a logical way based on the information flow through the experiments. In other words, the figures and tables alone can tell the story without consulting additional material. If all or some of these figures and tables are included in the final manuscript, make every effort to make them self-contained (see Rule 5 below), a favorable feature for the paper to have. In addition, these figures and tables, as well as the threading logical flow, may be used to direct or organize research activities, reinforcing Rule 1.
Rule 5: Be Thorough and Make It Complete
Completeness is a cornerstone for a research paper, following Rule 2. This cornerstone needs to be set in both content and presentation. First, important and relevant aspects of a hypothesis pursued in the research should be discussed with detailed supporting data. If the page limit is an issue, focus on one or two main aspects with sufficient details in the main text and leave the rest to online supporting materials. As a reminder, be sure to keep the details of all experiments (e.g., parameters of the experiments and versions of software) for revision, post-publication correspondence, or importantly, reproducibility of the results. Second, don't simply state what results are presented in figures and tables, which makes the writing repetitive because they are self-contained (see below), but rather, interpret them with insights to the underlying story to be told (typically in the results section) and discuss their implication (typically in the discussion section).
Third, make the whole paper self-contained. Introduce an adequate amount of background and introductory material for the right audience (following Rule 3). A statistical test, e.g., hypergeometric tests for enrichment of a subset of objects, may be obvious to statisticians or computational biologists but may be foreign to others, so providing a sufficient amount of background is the key for delivery of the material. When an uncommon term is used, give a definition besides a reference to it. Fourth, try to avoid “making your readers do the arithmetic” [9] , i.e., be clear enough so that the readers don't have to make any inference from the presented data. If such results need to be discussed, make them explicit even though they may be readily derived from other data. Fifth, figures and tables are essential components of a paper, each of which must be included for a good reason; make each of them self-contained with all required information clearly specified in the legend to guide interpretation of the data presented.
Rule 6: Be Concise
This is a caveat to Rule 5 and is singled out to emphasize its importance. Being thorough is not a license to writing that is unnecessarily descriptive, repetitive, or lengthy. Rather, on the contrary, “simplicity is the ultimate sophistication” [10] . Overly elaborate writing is distracting and boring and places a burden on the readers. In contrast, the delivery of a message is more rigorous if the writing is precise and concise. One excellent example is Watson and Crick's Nobel-Prize-winning paper on the DNA double helix structure [11] —it is only two pages long!
Rule 7: Be Artistic
A complete draft of a paper requires a lot of work, so it pays to go the extra mile to polish it to facilitate enjoyable reading. A paper presented as a piece of art will give referees a positive initial impression of your passion toward the research and the quality of the work, which will work in your favor in the reviewing process. Therefore, concentrate on spelling, grammar, usage, and a “lively” writing style that avoids successions of simple, boring, declarative sentences. Have an authoritative dictionary with a thesaurus and a style manual, e.g., [1] , handy and use them relentlessly. Also pay attention to small details in presentation, such as paragraph indentation, page margins, and fonts. If you are not a native speaker of the language the paper is written in, make sure to have a native speaker go over the final draft to ensure correctness and accuracy of the language used.
Rule 8: Be Your Own Judge
A complete manuscript typically requires many rounds of revision. Taking a correct attitude during revision is critical to the resolution of most problems in the writing. Be objective and honest about your work and do not exaggerate or belittle the significance of the results and the elegance of the methods developed. After working long and hard, you are an expert on the problem you studied, and you are the best referee of your own work, after all . Therefore, inspect the research and the paper in the context of the state of the art.
When revising a draft, purge yourself out of the picture and leave your passion for your work aside. To be concrete, put yourself completely in the shoes of a referee and scrutinize all the pieces—the significance of the work, the logic of the story, the correctness of the results and conclusions, the organization of the paper, and the presentation of the materials. In practice, you may put a draft aside for a day or two—try to forget about it completely—and then come back to it fresh, consider it as if it were someone else's writing, and read it through while trying to poke holes in the story and writing. In this process, extract the meaning literally from the language as written and do not try to use your own view to interpret or extrapolate from what was written. Don't be afraid to throw away pieces of your writing and start over from scratch if they do not pass this “not-yourself” test. This can be painful, but the final manuscript will be more logically sound and better organized.
Rule 9: Test the Water in Your Own Backyard
It is wise to anticipate the possible questions and critiques the referees may raise and preemptively address their concerns before submission. To do so, collect feedback and critiques from others, e.g., colleagues and collaborators. Discuss your work with them and get their opinions, suggestions, and comments. A talk at a lab meeting or a departmental seminar will also help rectify potential issues that need to be addressed. If you are a graduate student, running the paper and results through the thesis committee may be effective to iron out possible problems.
Rule 10: Build a Virtual Team of Collaborators
When a submission is rejected or poorly reviewed, don't be offended and don't take it personally. Be aware that the referees spent their time on the paper, which they might have otherwise devoted to their own research, so they are doing you a favor and helping you shape the paper to be more accessible to the targeted audience. Therefore, consider the referees as your collaborators and treat the reviews with respect. This attitude can improve the quality of your paper and research.
Read and examine the reviews objectively—the principles set in Rule 8 apply here as well. Often a criticism was raised because one of the aspects of a hypothesis was not adequately studied, or an important result from previous research was not mentioned or not consistent with yours. If a critique is about the robustness of a method used or the validity of a result, often the research needs to be redone or more data need to be collected. If you believe the referee has misunderstood a particular point, check the writing. It is often the case that improper wording or presentation misled the referee. If that's the case, revise the writing thoroughly. Don't argue without supporting data. Don't submit the paper elsewhere without additional work. This can only temporally mitigate the issue, you will not be happy with the paper in the long run, and this may hurt your reputation.
Finally, keep in mind that writing is personal, and it takes a lot of practice to find one's style. What works and what does not work vary from person to person. Undoubtedly, dedicated practice will help produce stronger papers with long-lasting impact.
Acknowledgments
Thanks to Sharlee Climer, Richard Korf, and Kevin Zhang for critical reading of the manuscript.
Funding Statement
The author received no specific funding for this article.

An official website of the United States government
Here’s how you know
Official websites use .gov A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS A lock ( Lock A locked padlock ) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.

In Spring 2021, the National Library of Medicine (NLM) PubMed® Special Query on this page will no longer be curated by NLM. If you have questions, please contact NLM Customer Support at https://support.nlm.nih.gov/
This chart lists the major biomedical research reporting guidelines that provide advice for reporting research methods and findings. They usually "specify a minimum set of items required for a clear and transparent account of what was done and what was found in a research study, reflecting, in particular, issues that might introduce bias into the research" (Adapted from the EQUATOR Network Resource Centre ). The chart also includes editorial style guides for writing research reports or other publications.
See the details of the search strategy. More research reporting guidelines are at the EQUATOR Network Resource Centre .
| American Medical Association
| A manuscript style guide for medical science. |
| American Psychological Association | Used in social and behavioral science studies. |
| Animal Research: Reporting of In Vivo Experiments | For reporting animal research and peer-reviewers of animal research studies.
|
| ASSERT: A Standard for the Scientific and Ethical Review of Trials | Research ethics committees use this guideline to review and monitor randomized clinical trials.
|
| reporting guidelines for CAse REports | Evidence-based, minimum recommendations for case reports. The CARE guidelines provide early signs of what may work for patients.
|
| Common Data Elements | Common data elements are standardized terms for the collection and exchange of data. CDEs are metadata; they describe the type of data collected, not the data itself. An example of metadata is the question presented on a form, "Patient Name," whereas an example of data would be "Jane Smith."
|
| Clinical Data Interchange Standards Consortium | Standards supporting the "acquisition, exchange, submission and archive of clinical research data and metadata."
|
| Consolidated Health Economic Evaluation Reporting Standards Statement | Used to report "economic evaluations of health interventions."
|
| Citation of BioResources in journal Articles | Developed by members of the journal editors’ subgroup of the Bioresource Research Impact Factor (BRIF) for citing bioresources, such as biological samples, data, and databases.
|
| Consolidated Standards of Reporting Trials | Evidence-based, 25-item checklist containing the minimum recommendations for reporting Randomized Clinical Trials (RCTs). |
| Committee on Publication Ethics | Forum for editors of peer-reviewed journals to discuss issues related to the integrity of the scientific record. Asks editors to report, record, and initiate investigations into ethical problems in the publication process. All Elsevier journals are COPE members.
|
| Consolidated criteria for reporting qualitative research | A "32-item checklist for interviews and focus groups."
|
| Council of Science Editors | Authority on scientific communication issues. |
| European Association of Science Editors | Remain aware of trends in traditional or electronic scientific publishing.
|
| Enhancing the QUAlity and Transparency Of health Research | Reporting guidelines developers, medical journal editors and peer reviewers, research funding bodies, and other partners work to improve the quality of research. |
| (formerly, Biosharing) | "A curated, informative and educational resource on data and metadata standards, inter-related to databases and data policies."
|
| Editorial Guidelines: Forum for African Medical Editors | 68-page guidelines includes the and the Helsinki Declaration.
|
| Guidelines for Neuro-Oncology: Standards for Investigational Studies | Guidelines to standardize reports of surgically-based Phase 1 and Phase 2 neuro-oncology trials.
|
| Good Publication Practice | Guidelines for the results of clinical trials sponsored by pharmaceutical companies. (To download a PDF of GPP 2022 from the Annals of Internal Medicine website, if you do not have a journal subscription.)
|
| Grey Literature International Steering Committee | Guidelines to produce scientific and technical reports and writing/distributing grey literature.
|
| Mulford Library, University of Toledo HSL | Lists in alphabetical order. Contains publishing guidelines for some journals. Indicates which journals follow CONSORT and/or other guidelines.
|
| International Committee of Medical Journal Editors | Uniform Requirements for Manuscripts Submitted to Biomedical Journals (also called the Vancouver Style)
|
| The aim is to improve the quality and credibility of scientific peer review and publication and to help advance the efficiency, effectiveness, and equitability of the dissemination of biomedical information throughout the world.
| |
| International Academy of Nursing Editors | To promote best practices in the nursing literature.
|
| Mayfield Handbook Investigation/Study/Assay (ISA) tab-delimited (TAB) format | "a general purpose framework with which to collect and communicate complex metadata (i.e. sample characteristics, technologies used, type of measurements made) from 'omics-based' experiments employing a combination of technologies."
|
| Minimum Information About a Microarray Experiment | The MIAME guideline is in Appendix B of Applications of Toxicogenomic Technologies to Predictive Toxicology and Risk Assessment (2007) at . Describes the basic data needed to enable the unambiguous interpretation of the results and to possibly replicate the experiment.
|
| Minimum Information for Biological and Biomedical Investigations | Portal of almost 40 checklists can use when reporting biological and biomedical science research.
|
| Meta-analysis of Observational Studies in Epidemiology | To report the meta-analyses of observational studies in epidemiology.
|
| Guidelines for Transparent Reporting of Outbreak Reports and Intervention studies Of Nosocomial infection | A 22-item checklist showing items to include when reporting an outbreak or intervention study of a nosocomial organism. Endorsed by professional special interest groups and societies, including the Association of Medical Microbiologists (AMM), British Society for Antimicrobial Chemotherapy (BSAC) & the Infection Control Nurses' Association (ICNA) Research and Development Group.
|
| PRIMER Collaboration: PRESENTATION AND INTERPRETATION OF MEDICAL RESEARCH | Group that aims to improve the design of studies, their presentation, interpretation of results and translation into practice.
|
| , National Institutes of Health (NIH) | NIH held a joint workshop in June 2014 with the Nature Publishing Group and Science on the issue of reproducibility and rigor of research findings, with journal editors representing over 30 basic/preclinical science journals in which NIH-funded investigators have most often published.
|
| Preferred Reporting Items for Systematic Reviews and Meta-Analyses (formerly, the QUOROM statement) | The is to help authors improve the reporting of systematic reviews and meta-analyses. It has “focused on randomized trials, but PRISMA can also be used as a basis for reporting systematic reviews of other types of research, particularly evaluations of interventions. PRISMA may also be useful for critical appraisal of published systematic reviews, although it is not a quality assessment instrument to gauge the quality of a systematic review.”
|
| QUOROM: QUality Of Reporting Of Meta-analyses (Renamed PRISMA in 2009) | Checklist that describes the preferred way to present the abstract, introduction, methods, results, and discussion sections of a report of a meta-analysis.
|
| Reporting Data on Homeopathic Treatments (A CONSORT Supplement) | Eight-item checklist to use by authors and editors when publishing reports of homeopathic clinical trials.
|
| Reporting guidElines For randomized controLled trials for livEstoCk and food safeTy | Evidence-based minimum set of items for trials reporting production, health, and food-safety outcomes. (22-item checklist)
|
| REporting recommendations for tumor MARKer prognostic studies | Guidelines for reporting of tumor marker studies.
|
| "Reporting practice guidelines in health care"
| |
| Sex and Gender Equity in Research | How to report sex and gender information in a study’s design, data analyses, results, and interpretation of findings.
|
| Standard Metabolic Reporting Structures | Recommendations for standardizing and reporting of metabolic analyses.
|
| Standard Protocol Items: Recommendations for Interventional Trials | The SPIRIT 2013 Statement is a 33-item checklist that recommend a minimum set of data to include in a clinical trial protocol.
|
| Revised Standards for Quality Improvement Reporting Excellence | The SQUIRE Guidelines help authors write usable articles about quality improvement in healthcare so that results are findable and widely distributed.
|
| Standards for reporting qualitative research: a synthesis of recommendations | How to report qualitative research.
|
| STAndards for the Reporting of Diagnostic accuracy | Aims to improve the accuracy and completeness of reporting of studies of diagnostic accuracy, to allow readers to assess the potential for bias in the study (internal validity) and to evaluate its generalizability. Checklist contains 34-items.
|
| Statement on Reporting of Evaluation Studies in Health Informatics | Used to report health informatics evaluation studies.
|
| STrengthening the REporting of Genetic Associations | To promote reporting of genetic association studies.
|
| : STandards for Reporting Interventions in Controlled Trials of Acupuncture (A CONSORT Supplement) | Designed as a supplement to CONSORT, which has led to improved reporting of trial design and conduct in general. Current plans are to revise STRICTA in collaboration with the CONSORT Group, such that STRICTA becomes an "official" extension to CONSORT.
|
| STrengthening the Reporting of OBservational studies in Epidemiology | Aims to establish a of items to include in articles reporting observational research.
|
| , National Library of Medicine (NLM) | Description of structured abstracts and how MEDLINE formats them.
|
| Updated guidance for reporting clinical prediction models that use regression or machine learning methods | "Reporting of studies that develop a prediction model or evaluate its performance."
|
| World Association of Medical Editors | Editors of peer-reviewed medical journals |
Last Reviewed: April 14, 2023
Style and Grammar Guidelines
APA Style provides a foundation for effective scholarly communication because it helps writers present their ideas in a clear, concise, and inclusive manner. When style works best, ideas flow logically, sources are credited appropriately, and papers are organized predictably. People are described using language that affirms their worth and dignity. Authors plan for ethical compliance and report critical details of their research protocol to allow readers to evaluate findings and other researchers to potentially replicate the studies. Tables and figures present information in an engaging, readable manner.
The style and grammar guidelines pages present information about APA Style as described in the Publication Manual of the American Psychological Association, Seventh Edition and the Concise Guide to APA Style, Seventh Edition . Any updates to APA Style are noted on the applicable topic pages. If you are still using the sixth edition, helpful resources are available in the sixth edition archive .
Looking for more style?

- Accessibility of APA Style
- Line Spacing
- Order of Pages
- Page Header
- Paragraph Alignment and Indentation
- Sample Papers
- Title Page Setup
- Appropriate Level of Citation
- Basic Principles of Citation
- Classroom or Intranet Sources
- Paraphrasing
- Personal Communications
- Quotations From Research Participants
- Secondary Sources
- Abbreviations
- Capitalization
- Italics and Quotation Marks
- Punctuation
- Spelling and Hyphenation
- General Principles for Reducing Bias
- Historical Context
- Intersectionality
- Participation in Research
- Racial and Ethnic Identity
- Sexual Orientation
- Socioeconomic Status
- Accessible Use of Color in Figures
- Figure Setup
- Sample Figures
- Sample Tables
- Table Setup
- Archival Documents and Collections
- Basic Principles of Reference List Entries
- Database Information in References
- DOIs and URLs
- Elements of Reference List Entries
- Missing Reference Information
- Reference Examples
- References in a Meta-Analysis
- Reference Lists Versus Bibliographies
- Works Included in a Reference List
- Active and Passive Voice
- Anthropomorphism
- First-Person Pronouns
- Logical Comparisons
- Plural Nouns
- Possessive Adjectives
- Possessive Nouns
- Singular “They”
- Adapting a Dissertation or Thesis Into a Journal Article
- Correction Notices
- Cover Letters
- Journal Article Reporting Standards (JARS)
- Open Science
- Response to Reviewers
- Article Information
Data Sharing Statement
- As Ozempic’s Popularity Soars, Here’s What to Know About Semaglutide and Weight Loss JAMA Medical News & Perspectives May 16, 2023 This Medical News article discusses chronic weight management with semaglutide, sold under the brand names Ozempic and Wegovy. Melissa Suran, PhD, MSJ
- Patents and Regulatory Exclusivities on GLP-1 Receptor Agonists JAMA Special Communication August 15, 2023 This Special Communication used data from the US Food and Drug Administration to analyze how manufacturers of brand-name glucagon-like peptide 1 (GLP-1) receptor agonists have used patent and regulatory systems to extend periods of market exclusivity. Rasha Alhiary, PharmD; Aaron S. Kesselheim, MD, JD, MPH; Sarah Gabriele, LLM, MBE; Reed F. Beall, PhD; S. Sean Tu, JD, PhD; William B. Feldman, MD, DPhil, MPH
- What to Know About Wegovy’s Rare but Serious Adverse Effects JAMA Medical News & Perspectives December 12, 2023 This Medical News article discusses Wegovy, Ozempic, and other GLP-1 receptor agonists used for weight management and type 2 diabetes. Kate Ruder, MSJ
- GLP-1 Receptor Agonists and Gastrointestinal Adverse Events—Reply JAMA Comment & Response March 12, 2024 Ramin Rezaeianzadeh, BSc; Mohit Sodhi, MSc; Mahyar Etminan, PharmD, MSc
- GLP-1 Receptor Agonists and Gastrointestinal Adverse Events JAMA Comment & Response March 12, 2024 Karine Suissa, PhD; Sara J. Cromer, MD; Elisabetta Patorno, MD, DrPH
- GLP-1 Receptor Agonist Use and Risk of Postoperative Complications JAMA Research Letter May 21, 2024 This cohort study evaluates the risk of postoperative respiratory complications among patients with diabetes undergoing surgery who had vs those who had not a prescription fill for glucagon-like peptide 1 receptor agonists. Anjali A. Dixit, MD, MPH; Brian T. Bateman, MD, MS; Mary T. Hawn, MD, MPH; Michelle C. Odden, PhD; Eric C. Sun, MD, PhD
- Glucagon-Like Peptide-1 Receptor Agonist Use and Risk of Gallbladder and Biliary Diseases JAMA Internal Medicine Original Investigation May 1, 2022 This systematic review and meta-analysis of 76 randomized clinical trials examines the effects of glucagon-like peptide-1 receptor agonist use on the risk of gallbladder and biliary diseases. Liyun He, MM; Jialu Wang, MM; Fan Ping, MD; Na Yang, MM; Jingyue Huang, MM; Yuxiu Li, MD; Lingling Xu, MD; Wei Li, MD; Huabing Zhang, MD
- Cholecystitis Associated With the Use of Glucagon-Like Peptide-1 Receptor Agonists JAMA Internal Medicine Research Letter October 1, 2022 This case series identifies cases reported in the US Food and Drug Administration Adverse Event Reporting System of acute cholecystitis associated with use of glucagon-like peptide-1 receptor agonists that did not have gallbladder disease warnings in their labeling. Daniel Woronow, MD; Christine Chamberlain, PharmD; Ali Niak, MD; Mark Avigan, MDCM; Monika Houstoun, PharmD, MPH; Cindy Kortepeter, PharmD
See More About
Select your interests.
Customize your JAMA Network experience by selecting one or more topics from the list below.
- Academic Medicine
- Acid Base, Electrolytes, Fluids
- Allergy and Clinical Immunology
- American Indian or Alaska Natives
- Anesthesiology
- Anticoagulation
- Art and Images in Psychiatry
- Artificial Intelligence
- Assisted Reproduction
- Bleeding and Transfusion
- Caring for the Critically Ill Patient
- Challenges in Clinical Electrocardiography
- Climate and Health
- Climate Change
- Clinical Challenge
- Clinical Decision Support
- Clinical Implications of Basic Neuroscience
- Clinical Pharmacy and Pharmacology
- Complementary and Alternative Medicine
- Consensus Statements
- Coronavirus (COVID-19)
- Critical Care Medicine
- Cultural Competency
- Dental Medicine
- Dermatology
- Diabetes and Endocrinology
- Diagnostic Test Interpretation
- Drug Development
- Electronic Health Records
- Emergency Medicine
- End of Life, Hospice, Palliative Care
- Environmental Health
- Equity, Diversity, and Inclusion
- Facial Plastic Surgery
- Gastroenterology and Hepatology
- Genetics and Genomics
- Genomics and Precision Health
- Global Health
- Guide to Statistics and Methods
- Hair Disorders
- Health Care Delivery Models
- Health Care Economics, Insurance, Payment
- Health Care Quality
- Health Care Reform
- Health Care Safety
- Health Care Workforce
- Health Disparities
- Health Inequities
- Health Policy
- Health Systems Science
- History of Medicine
- Hypertension
- Images in Neurology
- Implementation Science
- Infectious Diseases
- Innovations in Health Care Delivery
- JAMA Infographic
- Law and Medicine
- Leading Change
- Less is More
- LGBTQIA Medicine
- Lifestyle Behaviors
- Medical Coding
- Medical Devices and Equipment
- Medical Education
- Medical Education and Training
- Medical Journals and Publishing
- Mobile Health and Telemedicine
- Narrative Medicine
- Neuroscience and Psychiatry
- Notable Notes
- Nutrition, Obesity, Exercise
- Obstetrics and Gynecology
- Occupational Health
- Ophthalmology
- Orthopedics
- Otolaryngology
- Pain Medicine
- Palliative Care
- Pathology and Laboratory Medicine
- Patient Care
- Patient Information
- Performance Improvement
- Performance Measures
- Perioperative Care and Consultation
- Pharmacoeconomics
- Pharmacoepidemiology
- Pharmacogenetics
- Pharmacy and Clinical Pharmacology
- Physical Medicine and Rehabilitation
- Physical Therapy
- Physician Leadership
- Population Health
- Primary Care
- Professional Well-being
- Professionalism
- Psychiatry and Behavioral Health
- Public Health
- Pulmonary Medicine
- Regulatory Agencies
- Reproductive Health
- Research, Methods, Statistics
- Resuscitation
- Rheumatology
- Risk Management
- Scientific Discovery and the Future of Medicine
- Shared Decision Making and Communication
- Sleep Medicine
- Sports Medicine
- Stem Cell Transplantation
- Substance Use and Addiction Medicine
- Surgical Innovation
- Surgical Pearls
- Teachable Moment
- Technology and Finance
- The Art of JAMA
- The Arts and Medicine
- The Rational Clinical Examination
- Tobacco and e-Cigarettes
- Translational Medicine
- Trauma and Injury
- Treatment Adherence
- Ultrasonography
- Users' Guide to the Medical Literature
- Vaccination
- Venous Thromboembolism
- Veterans Health
- Women's Health
- Workflow and Process
- Wound Care, Infection, Healing
Others Also Liked
- Download PDF
- X Facebook More LinkedIn
Sodhi M , Rezaeianzadeh R , Kezouh A , Etminan M. Risk of Gastrointestinal Adverse Events Associated With Glucagon-Like Peptide-1 Receptor Agonists for Weight Loss. JAMA. 2023;330(18):1795–1797. doi:10.1001/jama.2023.19574
Manage citations:
© 2024
- Permissions
Risk of Gastrointestinal Adverse Events Associated With Glucagon-Like Peptide-1 Receptor Agonists for Weight Loss
- 1 Faculty of Medicine, University of British Columbia, Vancouver, British Columbia, Canada
- 2 StatExpert Ltd, Laval, Quebec, Canada
- 3 Department of Ophthalmology and Visual Sciences and Medicine, University of British Columbia, Vancouver, Canada
- Medical News & Perspectives As Ozempic’s Popularity Soars, Here’s What to Know About Semaglutide and Weight Loss Melissa Suran, PhD, MSJ JAMA
- Special Communication Patents and Regulatory Exclusivities on GLP-1 Receptor Agonists Rasha Alhiary, PharmD; Aaron S. Kesselheim, MD, JD, MPH; Sarah Gabriele, LLM, MBE; Reed F. Beall, PhD; S. Sean Tu, JD, PhD; William B. Feldman, MD, DPhil, MPH JAMA
- Medical News & Perspectives What to Know About Wegovy’s Rare but Serious Adverse Effects Kate Ruder, MSJ JAMA
- Comment & Response GLP-1 Receptor Agonists and Gastrointestinal Adverse Events—Reply Ramin Rezaeianzadeh, BSc; Mohit Sodhi, MSc; Mahyar Etminan, PharmD, MSc JAMA
- Comment & Response GLP-1 Receptor Agonists and Gastrointestinal Adverse Events Karine Suissa, PhD; Sara J. Cromer, MD; Elisabetta Patorno, MD, DrPH JAMA
- Research Letter GLP-1 Receptor Agonist Use and Risk of Postoperative Complications Anjali A. Dixit, MD, MPH; Brian T. Bateman, MD, MS; Mary T. Hawn, MD, MPH; Michelle C. Odden, PhD; Eric C. Sun, MD, PhD JAMA
- Original Investigation Glucagon-Like Peptide-1 Receptor Agonist Use and Risk of Gallbladder and Biliary Diseases Liyun He, MM; Jialu Wang, MM; Fan Ping, MD; Na Yang, MM; Jingyue Huang, MM; Yuxiu Li, MD; Lingling Xu, MD; Wei Li, MD; Huabing Zhang, MD JAMA Internal Medicine
- Research Letter Cholecystitis Associated With the Use of Glucagon-Like Peptide-1 Receptor Agonists Daniel Woronow, MD; Christine Chamberlain, PharmD; Ali Niak, MD; Mark Avigan, MDCM; Monika Houstoun, PharmD, MPH; Cindy Kortepeter, PharmD JAMA Internal Medicine
Glucagon-like peptide 1 (GLP-1) agonists are medications approved for treatment of diabetes that recently have also been used off label for weight loss. 1 Studies have found increased risks of gastrointestinal adverse events (biliary disease, 2 pancreatitis, 3 bowel obstruction, 4 and gastroparesis 5 ) in patients with diabetes. 2 - 5 Because such patients have higher baseline risk for gastrointestinal adverse events, risk in patients taking these drugs for other indications may differ. Randomized trials examining efficacy of GLP-1 agonists for weight loss were not designed to capture these events 2 due to small sample sizes and short follow-up. We examined gastrointestinal adverse events associated with GLP-1 agonists used for weight loss in a clinical setting.
We used a random sample of 16 million patients (2006-2020) from the PharMetrics Plus for Academics database (IQVIA), a large health claims database that captures 93% of all outpatient prescriptions and physician diagnoses in the US through the International Classification of Diseases, Ninth Revision (ICD-9) or ICD-10. In our cohort study, we included new users of semaglutide or liraglutide, 2 main GLP-1 agonists, and the active comparator bupropion-naltrexone, a weight loss agent unrelated to GLP-1 agonists. Because semaglutide was marketed for weight loss after the study period (2021), we ensured all GLP-1 agonist and bupropion-naltrexone users had an obesity code in the 90 days prior or up to 30 days after cohort entry, excluding those with a diabetes or antidiabetic drug code.
Patients were observed from first prescription of a study drug to first mutually exclusive incidence (defined as first ICD-9 or ICD-10 code) of biliary disease (including cholecystitis, cholelithiasis, and choledocholithiasis), pancreatitis (including gallstone pancreatitis), bowel obstruction, or gastroparesis (defined as use of a code or a promotility agent). They were followed up to the end of the study period (June 2020) or censored during a switch. Hazard ratios (HRs) from a Cox model were adjusted for age, sex, alcohol use, smoking, hyperlipidemia, abdominal surgery in the previous 30 days, and geographic location, which were identified as common cause variables or risk factors. 6 Two sensitivity analyses were undertaken, one excluding hyperlipidemia (because more semaglutide users had hyperlipidemia) and another including patients without diabetes regardless of having an obesity code. Due to absence of data on body mass index (BMI), the E-value was used to examine how strong unmeasured confounding would need to be to negate observed results, with E-value HRs of at least 2 indicating BMI is unlikely to change study results. Statistical significance was defined as 2-sided 95% CI that did not cross 1. Analyses were performed using SAS version 9.4. Ethics approval was obtained by the University of British Columbia’s clinical research ethics board with a waiver of informed consent.
Our cohort included 4144 liraglutide, 613 semaglutide, and 654 bupropion-naltrexone users. Incidence rates for the 4 outcomes were elevated among GLP-1 agonists compared with bupropion-naltrexone users ( Table 1 ). For example, incidence of biliary disease (per 1000 person-years) was 11.7 for semaglutide, 18.6 for liraglutide, and 12.6 for bupropion-naltrexone and 4.6, 7.9, and 1.0, respectively, for pancreatitis.
Use of GLP-1 agonists compared with bupropion-naltrexone was associated with increased risk of pancreatitis (adjusted HR, 9.09 [95% CI, 1.25-66.00]), bowel obstruction (HR, 4.22 [95% CI, 1.02-17.40]), and gastroparesis (HR, 3.67 [95% CI, 1.15-11.90) but not biliary disease (HR, 1.50 [95% CI, 0.89-2.53]). Exclusion of hyperlipidemia from the analysis did not change the results ( Table 2 ). Inclusion of GLP-1 agonists regardless of history of obesity reduced HRs and narrowed CIs but did not change the significance of the results ( Table 2 ). E-value HRs did not suggest potential confounding by BMI.
This study found that use of GLP-1 agonists for weight loss compared with use of bupropion-naltrexone was associated with increased risk of pancreatitis, gastroparesis, and bowel obstruction but not biliary disease.
Given the wide use of these drugs, these adverse events, although rare, must be considered by patients who are contemplating using the drugs for weight loss because the risk-benefit calculus for this group might differ from that of those who use them for diabetes. Limitations include that although all GLP-1 agonist users had a record for obesity without diabetes, whether GLP-1 agonists were all used for weight loss is uncertain.
Accepted for Publication: September 11, 2023.
Published Online: October 5, 2023. doi:10.1001/jama.2023.19574
Correction: This article was corrected on December 21, 2023, to update the full name of the database used.
Corresponding Author: Mahyar Etminan, PharmD, MSc, Faculty of Medicine, Departments of Ophthalmology and Visual Sciences and Medicine, The Eye Care Center, University of British Columbia, 2550 Willow St, Room 323, Vancouver, BC V5Z 3N9, Canada ( [email protected] ).
Author Contributions: Dr Etminan had full access to all of the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis.
Concept and design: Sodhi, Rezaeianzadeh, Etminan.
Acquisition, analysis, or interpretation of data: All authors.
Drafting of the manuscript: Sodhi, Rezaeianzadeh, Etminan.
Critical review of the manuscript for important intellectual content: All authors.
Statistical analysis: Kezouh.
Obtained funding: Etminan.
Administrative, technical, or material support: Sodhi.
Supervision: Etminan.
Conflict of Interest Disclosures: None reported.
Funding/Support: This study was funded by internal research funds from the Department of Ophthalmology and Visual Sciences, University of British Columbia.
Role of the Funder/Sponsor: The funder had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication.
Data Sharing Statement: See Supplement .
- Register for email alerts with links to free full-text articles
- Access PDFs of free articles
- Manage your interests
- Save searches and receive search alerts
Click through the PLOS taxonomy to find articles in your field.
For more information about PLOS Subject Areas, click here .
Loading metrics
Open Access
Peer-reviewed
Research Article
The state of artificial intelligence in medical research: A survey of corresponding authors from top medical journals
Contributed equally to this work with: Michele Salvagno, Alessandro De Cassai
Roles Conceptualization, Data curation, Methodology, Writing – original draft, Writing – review & editing
Affiliation Department of Intensive Care, Hôpital Universitaire de Bruxelles (HUB), Brussels, Belgium
Roles Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Writing – original draft, Writing – review & editing
* E-mail: [email protected] , [email protected] (AC)
Affiliation Sant’Antonio Anesthesia and Intensive Care Unit, University Hospital of Padua, Padua, Italy
Roles Writing – original draft, Writing – review & editing
Roles Visualization, Writing – original draft, Writing – review & editing
Affiliations Department of Mathematical Modelling and Artificial Intelligence, National Aerospace University “Kharkiv Aviation Institute”, Kharkiv, Ukraine, Ubiquitous Health Technologies Lab, University of Waterloo, Waterloo, Canada
Affiliation Department of Clinical Sciences and Community Health, Università degli Studi di Milano, Milan, Italy
Affiliation Department of Anesthesiology and Critical Care Medicine, Johns Hopkins University School of Medicine, Baltimore, MD, United States of America
Roles Supervision, Writing – original draft, Writing – review & editing
- Michele Salvagno,
- Alessandro De Cassai,
- Stefano Zorzi,
- Mario Zaccarelli,
- Marco Pasetto,
- Elda Diletta Sterchele,
- Dmytro Chumachenko,
- Alberto Giovanni Gerli,
- Razvan Azamfirei,
- Fabio Silvio Taccone
- Published: August 23, 2024
- https://doi.org/10.1371/journal.pone.0309208
- Peer Review
- Reader Comments
Natural Language Processing (NLP) is a subset of artificial intelligence that enables machines to understand and respond to human language through Large Language Models (LLMs)‥ These models have diverse applications in fields such as medical research, scientific writing, and publishing, but concerns such as hallucination, ethical issues, bias, and cybersecurity need to be addressed. To understand the scientific community’s understanding and perspective on the role of Artificial Intelligence (AI) in research and authorship, a survey was designed for corresponding authors in top medical journals. An online survey was conducted from July 13 th , 2023, to September 1 st , 2023, using the SurveyMonkey web instrument, and the population of interest were corresponding authors who published in 2022 in the 15 highest-impact medical journals, as ranked by the Journal Citation Report. The survey link has been sent to all the identified corresponding authors by mail. A total of 266 authors answered, and 236 entered the final analysis. Most of the researchers (40.6%) reported having moderate familiarity with artificial intelligence, while a minority (4.4%) had no associated knowledge. Furthermore, the vast majority (79.0%) believe that artificial intelligence will play a major role in the future of research. Of note, no correlation between academic metrics and artificial intelligence knowledge or confidence was found. The results indicate that although researchers have varying degrees of familiarity with artificial intelligence, its use in scientific research is still in its early phases. Despite lacking formal AI training, many scholars publishing in high-impact journals have started integrating such technologies into their projects, including rephrasing, translation, and proofreading tasks. Efforts should focus on providing training for their effective use, establishing guidelines by journal editors, and creating software applications that bundle multiple integrated tools into a single platform.
Citation: Salvagno M, Cassai AD, Zorzi S, Zaccarelli M, Pasetto M, Sterchele ED, et al. (2024) The state of artificial intelligence in medical research: A survey of corresponding authors from top medical journals. PLoS ONE 19(8): e0309208. https://doi.org/10.1371/journal.pone.0309208
Editor: Sanaa Kaddoura, Zayed University, UNITED ARAB EMIRATES
Received: November 22, 2023; Accepted: August 8, 2024; Published: August 23, 2024
Copyright: © 2024 Salvagno et al. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Data Availability: All relevant data are within the manuscript and its Supporting Information files.
Funding: The author(s) received no specific funding for this work.
Competing interests: The authors have declared that no competing interests exist.
Introduction
Artificial intelligence (AI) and machine learning systems are advanced computer systems designed to emulate human cognitive functions and perform a wide range of tasks independently. The giant leaps these systems provide are the possibility to learn and solve problems through autonomous decision-making if an adequate initial database is provided [ 1 ]. Natural Language Processing (NLP) represents a field within AI focused on enabling machines to understand, interpret, and respond to human language meaningfully.
One intriguing advancement within the realm of AI is the development of Large Language Models (LLMs), which are a subset of NLP technologies. They are characterized by billions of parameters, which allows them to process and generate human-like text, understanding and producing language across a wide range of topics and styles.Generative chatbots, like ChatGPT(Generative Pre-trained Transformer), Microsoft Copilot, or Google Gemini,enhance these models and offer an easy-to-use interface. These LLMs excel in natural language processing and text generation, making them invaluable for diverse applications. Specifically, they have been used in medical research for estimating adverse effects and predicting mortality in clinical settings [ 2 – 4 ], as well as in scientific writing and publishing [ 5 ]. Finally, domain-specific or fine-tuned modelsare models that undergo additional training on a specialized dataset and are tailored to specific areas of expertise. This allows these models to develop a deeper understanding of terminology, concepts, and contexts, making them more adept at handling tasks ina specific field.
Potential applications of AI, and more precisely LLMs, in scientific production, are vast and multi-faceted. These applications range from automated abstract generation to enhancing the fluency of English prose for non-native speakers and even streamlining the creation of exhaustive literature reviews [ 6 , 7 ]. However, AI output is far from being perfect, as AI hallucination has been well described and documented in the current literature [ 8 , 9 ]. Additional concerns include ethical, copyright, transparency, and legal issues, the risk of bias, plagiarism, lack of originality, limited knowledge, incorrect citations, cybersecurity issues, and the risk of infodemics [ 9 ].
In light ofAI’s novel application in scientific production, it remains unclear to what extent the scientific community understands its inherent potentials, limitations, and potential applications. To address this, the authors designed a survey to examine the level of familiarity, understanding, and perspectives among contributing authors in premier medical journals regarding the role and impact of artificial intelligence in top scientific research and authorship. We hypothesize that, given the novelty of large language models (LLMs), researchers might not be familiar with their use and may not have implemented them in their daily practice.
Survey design
An online survey in this study was conducted using the SurveyMonkey web instrument ( https://www.surveymonkey.com , SurveyMonkey Inc., San Mateo, California, USA). The survey protocol (P2023/262) was approved by the Hospitalo-FacultaireErasme–ULB ethical commission(Comitéd’Ethiquehospitalo-facultaireErasme–ULB, chairman: Prof. J.M. Boeynaems) on July 11 th , 2023.
Two members of the survey team (M.S. and A.D.C.) performed a bibliographic search on April 19, 2023, on PubMed and Scopus, to retrieve any validated questionnaire on the topic using the following search string: [((Artificial Intelligence) OR (ChatGPT) OR (ChatBot)) AND ((scientific production) OR (scientific writing)) AND (survey)]. No existing surveys on the specific topic were found.
Therefore, the research team constructed the questionnaire under the BRUSO acronym to create a well-constructed survey [ 10 ]. The survey consisted of 20 single-choice, multiple-choice, and open-ended questions investigating individuals’ perceptions of using Artificial Intelligence (AI) in scientific production and content. The full list of questions is available for consultation in English ( S1 Appendix Content 1, Survey Questionnaire in English).
Population of interest
The population of interest in this survey consisted of corresponding authors who published in 2022 in the 15 highest-impact medical journals ( S2 Appendix Content 2), as ranked by the Journal Citation Report from Clarivate. In this survey, we used the Journal Impact Factor (JIF) as a benchmark to target leading publications in the research field. Originally developed by Eugene Garfield in the 1960s, the JIF is frequently employed as a proxy for a journal’s relative importance within its discipline. It is calculated by dividing the number of citations in a given year to articles published in the preceding two years by the total number of articles published in those two years. The focus on the corresponding authors aimed to access a segment of the research community that is potentially at the forefront of research publishing and scientific production. For this survey, only the email addresses of the corresponding authors listed in the manuscript were sought and collected. Whenmultiple emails were listed as corresponding, only the first email for each article was collected.When no email addresses were found, no further steps were taken to retrieve them.No differentiation was made regarding the type of published article, except for excluding memorial articles dedicated to deceased colleagues. All other articles were included. The authenticity of the email addresses or their correspondence with the author’s name was not verified. As a result, it was not possible to calculate the a priori sample size.
Survey distribution plan
To enhance the survey’s effectiveness, a pretest was performed in two phases. In the first phase, the survey team reviewed the entire survey, with particular attention to the flow and the order of the questions to avoid issues with “skip” or “branch” logic. The time required to complete the survey was estimated to be around four minutes. In the second phase,the survey was distributed for validation to a small subset of participants, which included researchers working at the Erasme Hospital, to identify any issues before distributing it to the general population of interest. Their answers were not included in the final data analysis.
UsingSurveyMonkey’s email distribution feature, the survey link was disseminated to all collected email addresses of the corresponding authors. To minimize the ratio of non-responders, reminder emails were sent one, two, and three weeks after the initial contact, with a final reminder sent one month later. Responses were collected from July 13 th , 2023, to September 1 st , 2023. SurveyMonkey’s web instrument automatically identifies respondents and non-respondents through personalized links, allowing for targeted reminders to only those who had not yet completed the survey. This system also automatically prevents duplicate responses.
Statistical analysis
Descriptive statistics was used to provide an overview of the dataset. Depending on the nature of the variables the results are reported either as percentages or as medians with interquartile range (IQR). Comparison among percentages were performed with the chi-square test with a p-values significance threshold at 0.05. All statistical analyses were performed using Jamovi (Jamovi, Sydney, NSW Australia, Version 2.3) and GraphPad Prism (GraphPad Software, Boston, Massachusetts USA,Version 10).
A total of 4,302 email addresses for inclusion in the survey were collected from the list of journals in the appendix. Survey data were collected from 13 th July to 1 st September 2023. Following the initial email outreach and four subsequent reminders, 222 emails bounced back, and 142 recipients actively opted out of participating.Of those who opened the survey link, 266 respondents answered the initial questions. However, some immediately declined to continue, resulting in 236(5.5% of the emails sent) participants who started the survey and were included in the final analysis upon response.
The geographical distribution and demographic data of 229 respondents are depicted in Table 1 ,.The United States and the United Kingdom were most prominently represented, accounting for 57 (24.9%) and 41 (17.9%) of respondents, respectively. In total, English-speaking nations (USA, UK, Canada, and Australia) accounted for 124 (54.1%) of respondents.
- PPT PowerPoint slide
- PNG larger image
- TIFF original image
https://doi.org/10.1371/journal.pone.0309208.t001
The role of 229 responders is represented in Fig 1 . Physicians, research academics and research clinicians were equally represented, with 64 (27.9%), 65 (28.4%) and 67 (29.2%) responders, respectively. The other responders declared not to be classified as the aforementioned and explained themselves mainly as journalists, students, veterinarians, editors, and pharmacists.
Proportion of respondents in various professional roles as a percentage of the total respondent pool.
https://doi.org/10.1371/journal.pone.0309208.g001
Most of the respondents to this question reported moderate 93 (40.6%) or little 60 (26.2%) familiarity with AI tools. Only 13 (5.7%) indicated extensive familiarity.Following questions up to Q14 were answered by all participants except for the 10 individuals (4.4%) who indicated no prior knowledge of AI (resulting in their automatic exclusion from answering those specific questions). Notably, 9 (69.2%)out of 13 with extensive familiarity reported AI tool usage, compared to lower rates among 20 out of 93 (21.5%)with moderate and 5 out of 60 (8.3%)minimal familiarity (p < 0.001).
More than half of 229 respondents (130, 55%) published their first medical article over 15 years ago, while 31 (13.5%) did so within the last five years. The median Scopus H-index among respondents was 24 (IQR 13–42). No statistically significant correlations were identified between H-index, AI familiarity and AI usage (p > 0.05).
Only 2 participants (< 1%), reported receiving specific training in AI for scientific production. Despite this, 55 (24.02%) out of 229 responders usedAI tools in scientific content creation.Of these, the majority (67.3%) used ChatGPT. Interestingly, among participants from the US(n = 57), a notable difference exists between those who have used AI for scientific production(n = 8, 14%) and those who have not (n = 49, 86%).Those who published the first medical article more than 15 years ago, also declared to have ever used AI tools for scientific production in a lesser amount than the ones who published the first medical article less than 15 years ago(23/130 [17.7%] vs. 32/99 [32.3%], p = 0.01).
As shown in Fig 2 , besides ChatGPT, among the 55 responders who have already published using the aid of AI during the scientific production,Microsoft Bing and Google Bard were used by 8 (14.5%) and 2 (3.6%) of respondents, respectively. Other large language models comprised 5.0% of the usage. Various software tools, including image creation and meta-analysis assistant tools, were also reported to be used by 7 (12.7%) and 6 (10.9%), respectively. Other AI tools reported are mainly Grammarly, Image Analysis tools, and plagiarism-checking tools.
The Y-axis lists the AI tools reported by respondents, while the X-axis shows their stated usage as a percentage. The total percentage exceeds 100% as respondents could report using multiple tools. LLM: Large Language Models; AI: Artificial Intelligence.
https://doi.org/10.1371/journal.pone.0309208.g002
When the 55 respondents who already used AI tools were asked about the primary applications of AI, 55.6% reported using AI for rephrasing text, 33.3% for translation, and 37.78% for proofreading. The rate of AI usage for language translation was consistent across English and non-English-speaking countries (94.4% vs 92.4%,p = 0.547). Additional applications such as draft writing, idea generation, and information synthesis were each noted by 24.4% of respondents.
In the survey, 8 of the 51 who answered this question (15.7%) admitted to using a chatbot for scientific work without acknowledgment.By contrast, 27 (11.9%)out of 226 are certain they will employ some form of Artificial Intelligence in future scientific production. The complete set of responses is summarized in Table 2 .
https://doi.org/10.1371/journal.pone.0309208.t002
The primary challenges associated with utilizing AI in scientific research are outlined in Table 3 .
https://doi.org/10.1371/journal.pone.0309208.t003
The medical fields that respondents anticipate will gain the most from AI applications are Big Data Management and Automated Radiographic Report Generation. Additionalareas are detailed in Table 4 .
https://doi.org/10.1371/journal.pone.0309208.t004
When asked about their ability to distinguish between text written by a human and text generated by AI, 7 (3.1%) out of 226 respondents believed they could always tell the difference. Meanwhile, 120 (53.1%) felt they could only sometimes discern the difference. A total of 59 (26%)were uncertain, and a small fraction, 3 (1.3%), reported it is never possible to distinguish between the two.
Over 80% of respondents (n = 226) do not foresee AI supplanting the role of medical researchers in the future, with 81 (35.8%)strongly disagreeing and 106 (46.9%)disagreeing. A small fraction, 10 responders (4.4%), either somewhat or strongly agree that AI could take on the role of medical researchers. Meanwhile, 29 (12.8%)remain uncertain. By contrast, when it comes to the impact on clinical physicians,among the 226 responders to this last question, 177(78.3%) anticipate that AI will partially alter the nature of their work within the next two decades. A minority of 18 responders (8.0%) foresee no change at all, and a very small fraction, 2 (0.9%), predict a complete transformation in the role of clinical physicians. To conclude, 14 (6.0%)are still unsure about the future impact of AI on clinical practice.
The present study aimed to explore the perceptions and utilization of Artificial Intelligence (AI) tools in scientific production among corresponding authors who published in the 15 most-impacted factor medical journals in 2022.
Familiarity and training in AI
Intriguingly, this survey indicated that less than 1% of respondents had undergone formal training specifically designed for the application of AI in scientific research. This highlights a critical need for educational programs tailored to empower researchers with the necessary skills for effective AI utilization. The dearth of formal training may also contribute to the observed "limited" to "moderate" familiarity with AI concepts and tools among most survey participants, without a difference among ages and genders.Generally, AI tools are user-friendly and straightforward, requiring no specialized skills for basic usage. This could account for the lack of a significant difference between younger and older users.However, even though the basic use appears straightforward, a lack of comprehension may lead individuals to commit unnoticed errors with these tools, stemming from an unawareness of their own knowledge gaps [ 11 ].
Although beyond the primary focus of this study, we find it noteworthy to comment on the responses concerning the Scopus H-index. This score remains a subject of debate and is fraught with limitations, including self-citation biases, equal attribution regardless of author order and academic age,as well as gender-based disparities other than topic-specific biases. In our survey, the responders presented a median H-index of 24 (IQR 13–42), without statistically significant correlationsbetween H-index values and the variables of interest. Remarkably, two respondents indicated a lack of interest in monitoring their H-index. One respondent, a journal editor, expressed outright indifference with the remark "Who cares", probably echoing a sentiment that could be ascribed to Nobel Laureate Tu Youyou, whose current relatively low Scopus H-index of 16 belies her groundbreaking work on artemisinin, a treatment for malaria that has saved millions of lives.
Applications of AI in scientific production
The survey results underscore a paradoxical relationship between familiarity with AI concepts and its actual utilization in scientific production. While many respondents indicated a “limited” to “moderate” familiarity with AI, around 25% reported employing AI tools in their research endeavors. This suggests that while the theoretical understanding of AI might be limited among the surveyed population, its practical applications are cautiously being explored. It is plausible that the rapid advancements in AI, coupled with its increasing accessibility, have allowed researchers to experiment with these tools without necessarily delving deep into the underlying algorithms and principles.Notably, the preponderance of the surveyed gravitated toward ChatGPT, suggesting a proclivity for natural language processing applications. Indeed, ChatGPT could assist scientists in scientific production in several ways [ 12 ].
The principal tasks for which AI was employed encompassed rephrasing, translation, and proofreading functions. AI tools, especially natural language processing models like ChatGPT, can significantly improve the fluency and coherence of scientific texts, especially for non-native English speakers. This is crucial in the globalized world of scientific research, where effective communication can determine the reach and impact of a study. Interestingly, the rates of AI use for language translation were quite similar between English-speaking and non-English-speaking countries, at 94.4% and 92.4%, respectively. This is unexpected since English is often the preferred language for communication in scientific fields, diminishing the perceived need for translation tools. Several factors could explain this trend. First, these countries have a high proportion of expatriates, leading to many non-native English speakers in the workforce. One limitation of our study is that we did not inquire about the respondents’ countries of origin, so we cannot provide further insights. Another possible explanation could be the selectivity of our respondent pool, which may not be sufficiently representative to show a difference in this variable.Nevertheless, ifthe predominant use of AI for tasks such as rephrasing, translation, and proofreading underscores its potential to enhance the quality of research output, it is essential to strike a balance to ensure that the essence and originality of the research are maintained in the pursuit of linguistic perfection.
This pattern intimates that, in its current stage, AI is predominantly perceived as a facilitator for enhancing the textual quality of scholarly work, rather than as an instrument for novel research ideation or data analysis. In response to this evolving landscape, academic journals, for example, JAMA and Nature, have issued guidelines concerning the judicious use of large language models (LLMs) and generative chatbots [ 13 , 14 ]. Such guidelines often stipulate authors’ need to disclose any AI-generated content explicitly, including the specification of the AI model or tool deployed.
While the survey highlighted the use of LLMs predominantly in textual enhancements, the potential of other AI in data analysis still needs to be explored among the respondents. Indeed, LLM and NLP, in general, currently have a very weak theoretical basis for data prediction.Nevertheless, longitudinal electronic health record (EHR) data have been effectively tokenized and modeled using transformer approaches, to integrate different patient measurements, as reported in the field of Intensive Care Medicine [ 15 ], even if this field is still insufficiently explored. Advanced AI algorithms can process vast datasets, identify patterns, and even accurately predict future trends, often beyond human capabilities. For instance, in biomedical research, numerous machine learning applications tailored to specific tasks or domains can assist in analyzing complex genomic data, predicting disease outbreaks, or modeling the effects of potential drugs. As indicated by the survey, the limited utilization of AI in these areas may be due to the lack of specialized training or apprehensions about the reliability of AI-generated insights.
Future prospects
Most respondents were optimistic about the future role of AI in scientific production, with nearly 12% stating they would "surely" use AI in the future. This optimism towards integrating AI in scientific production can be attributed to the numerous advancements and breakthroughs in AI in recent years. As AI models become more sophisticated, their potential applications in research expand, ranging from data analysis and visualization to hypothesis generation and experimental design. The increasing availability of open-source AI tools and platforms makes it more accessible for researchers to incorporate AI into their work, even without extensive technical expertise.
However, most respondents (> 80%) did not believe that AI would replace medical researchers, suggesting a balanced view that AI will serve as a complementary tool rather than a replacement for human expertise. The sentiment that AI will augment rather than replace human expertise aligns with the broader perspective in the AI community, often termed “augmented intelligence” [ 16 ]. This perspective emphasizes the synergy between human intuition and AI’s computational capabilities. While AI can handle vast amounts of data and rapidly perform complex calculations, human researchers bring domain expertise, critical thinking, and ethical considerations [ 17 ]. This combination can lead to more robust and comprehensive research outcomes [ 16 , 18 ].
Moreover, the evolving landscape of AI in research also presents opportunities for interdisciplinary collaboration [ 19 ]. As AI becomes more integrated into scientific research, there will be a growing need for collaboration between AI specialists and domain experts. Such collaborations can ensure that AI tools are developed and applied in contextually relevant and scientifically rigorous ways. This interdisciplinary approach can lead to novel insights and innovative solutions to complex research challenges.
Ethical and technical concerns
This survey identified a wide range of concerns regarding the integration of Artificial Intelligence (AI) into the realm of scientific research. Among these, content inaccuracies emerged as the most salient, flagged by over 80% of respondents. The risks associated with AI-generated content include creating ostensibly accurate but factually erroneous data, such as fabricated bibliographic references, a phenomenon described as "Artificial Intelligence Hallucinations"[ 20 ]. It has already been proposed that the Dunning-Kruger effect serves as a pertinent framework to consider the actual vs. the perceived competencies that exist regarding the application of AI in research [ 21 ]. Furthermore,the attitudes and expectations surrounding such technologies, just one year following the release of OpenAI’s ChatGPT, can be aptly illustrated by the Gartner Hype Cycle [ 22 ]. Consequently, it is imperative that content generated by AI algorithms, even translations, undergo rigorous validation by subject matter experts.
Moreover, the rapid evolution of AI models, especially deep learning architectures, has created ’black box’ systems where the decision-making process is not transparent [ 23 ]. This opacity can further exacerbate researchers’ trust issues towards AI-generated content. The lack of interpretability can hinder the widespread adoption of AI in scientific research, as researchers might be hesitant to rely on tools they need to understand fully. Efforts are being made in the AI community to develop more interpretable and explainable AI models, but the balance between performance and transparency remains a challenge [ 24 ].
Beyond the ethical implications, another emerging concern is the potential for AI to perpetuate existing biases in the training data or continue "citogenesis"[ 25 ], which represents an insidious form of error propagation within the scientific corpus [ 26 ]. If AI models are trained on biased datasets, they can produce skewed or discriminatory results, leading to flawed conclusions and the perpetuation of systemic inequalities in research. This is particularly concerning in social sciences and medicine, where biased conclusions can have far-reaching implications [ 27 ]. For this reason, researchers must be aware of these pitfalls and advocate for the usage of data that is as unbiased and representative as possible in training AI models. The full spectrum of potential negative outcomes remains largely unquantified. Furthermore, using AI complicates the attribution of accountability, particularly in clinical settings. Ethical concerns, echoed by most of our respondents, coexist with legal considerations [ 28 ].
Additionally, integrating AI into scientific research raises data privacy and security questions [ 29 ]. As AI models often require vast amounts of data for continued training,there is the risk of submitted sensitive information being unintentionally exposed or misused during the process.This is one of the main reasons why several AI companies recently came out with enterprise and on-premise software versions.Such measures are especially pertinent in medical research, where patient data confidentiality is paramount [ 23 , 30 ]. Ensuring robust data encryption and adhering to stringent data handling protocols becomes crucial when incorporating AI into the research workflow.
Various policy options have been tabled to govern the use of AI in the production and editing of scholarly texts. These range from a complete prohibition on using AI-generated content in academic manuscripts to mandates for clear disclosure of AI contributions within the text and reference sections [ 31 ]. Notably, accrediting AI systems as authors appear to be universally rejected.Given these challenges, the concerns identified are legitimate and necessitate comprehensive investigation, particularly as AI technologies continue to advance and diversify in application.
A collaborative approach that includes AI experts, ethicists, policymakers, and researchers is crucial to manage the ethical and technical complexities and fully leverage AI in a responsible and effective manner. Furthermore, it is advisable for journal editors to establish clear guidelines for AI use, as some have already begun [ 14 ], including mandating the disclosure of AI involvement in the research process. Strict policies should be implemented to safeguard the data utilized by AI systems. Human oversight is necessary to interpret the data and results produced by AI. Additionally, an independent group should assess the impact of AI on research outcomes and ethical issues.
Lastly, attention must be paid to the energy consumption of AI systems and their consequent carbon footprint, which can be considerable, especially in the case of large-scale computational models [ 32 ]. AI and machine learning models, particularly those utilizing deep learning, require extensive computational resources and use significant amounts of electricity. To minimize this footprint, researchers should focus on optimizing AI algorithms to increase their energy efficiency and employ these systems only when absolutely necessary. It is essential for researchers to consider the environmental impact of their AI usage, treating ecological sustainability as a critical factor in today’s world.
Future in healthcare
The advent of AI in healthcare is rapidly evolving, and our responders anticipate Big Data Management [ 33 ] and Automated Radiographic Report Generation [ 34 ] to be the most impactful areas influenced by AI applications in the next few years. These results underline the growing recognition of AI’s transformative potential in these domains [ 35 ]. Indeed, the current healthcare landscape generates massive amounts of data from diverse sources, including electronic health records, diagnostic tests, and patient monitoring systems [ 36 ]. AI-powered analytics tools could revolutionize how we understand and interpret this data, thus aiding in more accurate diagnosis and personalized treatment protocols. Similarly, medical imaging studies require considerable time and expertise for interpretation, representing a potential bottleneck in clinical workflow. Automated systems powered by AI can analyze images and rapidly generate reports with a speed and consistency that could vastly improve throughput and possibly contribute to improved patient outcomes, bolstering the assumption that AI-assisted radiologists work better and faster [ 37 ]. By contrast, these systems have been demonstrated to generate more incorrect positive results compared to radiology reports, especially when dealing with multiple or smaller-sized target findings [ 38 ]. Despite these and other limitations such as privacy security concerns, computer-aided diagnosis is promising and could impact several specialties [ 39 ]. In the market, there are already various user-friendly and easy-to-use mobile apps available, designed for healthcare professionals as well as patients, that offer quick access to artificial intelligence tools for obtaining potential diagnoses.Nevertheless, AI currently lacks the precision and capability to make clinical diagnoses, and thus cannot be a substitute for a doctor.
Finally, the development of AI in diagnosis and drug development was also highly rated in the survey. These results mirror current research trends, where AI has been applied for early disease detection and drug discovery processes, significantly cutting down time and costs. Even so, the essential human interaction between patient and clinician remains a core aspect of medical care, making it unlikely that AI will soon replace the need for in-person connection [ 40 ]. Our survey respondents echo this sentiment, as the majority believe clinical doctors will only be partially replaced by technological advancements. Interestingly, in the open-ended responses, among the others, we found this comment “Humans do not want an AI-doctor”. Even though literature tells us that AI could be more empathetic than human doctors [ 41 ], for the moment, everyone agrees.
Limitations
While this study provides valuable insights into the understanding and utilization of Artificial Intelligence (AI) in scientific research, there are some noteworthy limitations. First, the study sample focuses exclusively on corresponding authors from high-impact medical journals. Although this allows us to capture perspectives from researchers at the forefront of scientific advancements, it may limit the generalizability of our findings to the broader scientific and medical community, including early-career researchers and students. Future surveys should aim to include a more diverse range of participants for a fuller picture.
Second, the survey had a low response rate. Physicians are generally challenging to be involved in survey research, and web-based surveys often yield lower participation rates [ 42 ]. Additionally, the accuracy of the email addresses is not guaranteed in email surveys, as evidenced by the emails that were bounced back, likely due to outdated or incorrect institutional email addresses. Nevertheless, although we didn’t conduct an a priori sample size calculation, our aim was to collect responses from at least 300 participants to obtain a substantial perspective on the subject.
Third, the data was gathered through an online survey, which might introduce selection bias as those who are more comfortable with technology and AI may have been more inclined to participate.
Fourth, there was no verification process for the authenticity of the email addresses used in our study, which leaves room for potential inaccuracies in the data collected.
Conclusions
This survey revealed varying degrees of familiarity with AI tools among researchers, with many in high-impact journals beginning to integrate AI into their work. The majority of respondents were from the USA and UK, with 54.1% from English-speaking countries. Only 5.7% indicated extensive familiarity with AI, and 24% used AI tools in scientific content creation, predominantly ChatGPT. Despite low training rates in AI (less than 1%), its use is gradually becoming more prevalent in scientific research and authorship.
Supporting information
S1 appendix. survey questionnaire..
https://doi.org/10.1371/journal.pone.0309208.s001
S2 Appendix. List of the leading 15 medical journals by impact factor.
https://doi.org/10.1371/journal.pone.0309208.s002
- View Article
- PubMed/NCBI
- Google Scholar
- 14. Artificial Intelligence (AI) | Nature Portfolio n.d. https://www.nature.com/nature-portfolio/editorial-policies/ai (accessed April 15, 2024).
- 25. 978: Citogenesis ‐ explain xkcd n.d. https://www.explainxkcd.com/wiki/index.php/978:_Citogenesis (accessed September 3, 2023).
More From Forbes
Nist ratifies quantum safe algorithms co-developed by ibm research.
- Share to Facebook
- Share to Twitter
- Share to Linkedin
The National Institute of Standards and Technology (NIST) has confirmed three algorithms co-developed by IBM Research, which are used to protect sensitive infrastructure and data from attacks by bad actors using Quantum Computers to break the existing encryption .
As we have discussed before in these pages, the cryptography used in every computer in the world will need to be updated, and soon, to be safe from the power of cryptographically relevant quantum computers to break security. IBM has been helping its clients make cryptosystems resilient for the quantum era by establishing cryptographic agility, or crypto-agility for short.
The US NIST has now approved three of the new algorithms being used. Crypto-agility means that a system, platform, application, or organization can rapidly adapt its cryptographic mechanisms and algorithms in response to changing threats, technological advances, or vulnerabilities. Achieving this goal is complex, but IBM has tools and services to help organizations adapt cryptographic architecture, implement automation, and provide governance to allow for greater control and flexibility to anticipate evolving cyber threats efficiently with minimal disruption.
Algorithms approved by NIST
Three IBM Research algorithms validated (and renamed) by the NIST include one for general encryption, ML-KEM, and two for digital signature verification, ML-DSA and SLH-DSA. In addition, IBM has three more (with creative names like “Unbalanced Oil and Vinegar” and “Mayo”) under consideration.
The three algorithms accepted by the NIST include general encryption, intrusion prevention, and a ... [+] signature scheme.
IBM helps clients secure their digital environment using two primary solutions. The first, the IBM Quantum Safe Explorer, scans code across applications and finds the high-impact cryptography that need to be remediated as soon as possible, helping prioritize the work to be done. IBM Quantum Safe Remediator provides network and code remediation utilities for QS migration and crypto-agility and provides the ability to enhance cyber resilience by protecting applications and networks and optimize performance before deployment to ensure crypto-agility
The Roadmap to a quantum-safe infrastructure.
Today’s NYT Mini Crossword Clues And Answers For Wednesday, August 28th
Microsoft update leak—good news revealed for 30% of windows users, trump staffers reportedly had physical altercation with arlington national cemetery official, conclusions.
There are quite a few research projects underway across the industry to develop useful quantum computing technologies. While there are many different viewpoints on when some of these could bear fruit, IBM is thinking the big game. IBM is developing the tools and the community that can prepare for a world where some problems will best be solved with quantum computing. Helping their customers secure their existing infrastructure against quantum-enabled attackers is foundational to IBM, and their clients.
Disclosures : This article expresses the opinions of the author and is not to be taken as advice to purchase from or invest in the companies mentioned. My firm, Cambrian-AI Research, is fortunate to have many semiconductor firms as our clients, including BrainChip, Cadence, Cerebras Systems, D-Matrix, Esperanto, Groq, IBM, Intel, Micron, NVIDIA, Qualcomm, Graphcore, SImA,ai, Synopsys, Tenstorrent, Ventana Microsystems, and scores of investors. We have no investment positions in any of the companies mentioned in this article. For more information, please visit our website at https://cambrian-AI.com .

- Editorial Standards
- Reprints & Permissions
Join The Conversation
One Community. Many Voices. Create a free account to share your thoughts.
Forbes Community Guidelines
Our community is about connecting people through open and thoughtful conversations. We want our readers to share their views and exchange ideas and facts in a safe space.
In order to do so, please follow the posting rules in our site's Terms of Service. We've summarized some of those key rules below. Simply put, keep it civil.
Your post will be rejected if we notice that it seems to contain:
- False or intentionally out-of-context or misleading information
- Insults, profanity, incoherent, obscene or inflammatory language or threats of any kind
- Attacks on the identity of other commenters or the article's author
- Content that otherwise violates our site's terms.
User accounts will be blocked if we notice or believe that users are engaged in:
- Continuous attempts to re-post comments that have been previously moderated/rejected
- Racist, sexist, homophobic or other discriminatory comments
- Attempts or tactics that put the site security at risk
- Actions that otherwise violate our site's terms.
So, how can you be a power user?
- Stay on topic and share your insights
- Feel free to be clear and thoughtful to get your point across
- ‘Like’ or ‘Dislike’ to show your point of view.
- Protect your community.
- Use the report tool to alert us when someone breaks the rules.
Thanks for reading our community guidelines. Please read the full list of posting rules found in our site's Terms of Service.
IMAGES
COMMENTS
Here are a few best practices: Your results should always be written in the past tense. While the length of this section depends on how much data you collected and analyzed, it should be written as concisely as possible. Only include results that are directly relevant to answering your research questions.
Reporting Research Results in APA Style | Tips & Examples. Published on December 21, 2020 by Pritha Bhandari.Revised on January 17, 2024. The results section of a quantitative research paper is where you summarize your data and report the findings of any relevant statistical analyses.. The APA manual provides rigorous guidelines for what to report in quantitative research papers in the fields ...
Present the results of the paper, in logical order, using tables and graphs as necessary. Explain the results and show how they help to answer the research questions posed in the Introduction. Evidence does not explain itself; the results must be presented and then explained. Avoid: presenting results that are never discussed; presenting ...
Practical guidance for writing an effective results section for a research paper. Always use simple and clear language. Avoid the use of uncertain or out-of-focus expressions. The findings of the study must be expressed in an objective and unbiased manner. While it is acceptable to correlate certain findings in the discussion section, it is ...
Research results refer to the findings and conclusions derived from a systematic investigation or study conducted to answer a specific question or hypothesis. These results are typically presented in a written report or paper and can include various forms of data such as numerical data, qualitative data, statistics, charts, graphs, and visual aids.
For example, authors can check specific guidelines when writing the Results section such as STROBE for observational studies, 19 CONSORT for clinical trials, 18 SRQR 20 and COREQ 21 for qualitative research, MMAT for mixed method designs 22 and PRISMA 23 and JBI 24 for systematic reviews and meta-analyses. Online guidelines are also available ...
The results section of a research paper tells the reader what you found, while the discussion section tells the reader what your findings mean. The results section should present the facts in an academic and unbiased manner, avoiding any attempt at analyzing or interpreting the data. Think of the results section as setting the stage for the ...
Developing a well-written research paper is an important step in completing a scientific study. This paper is where the principle investigator and co-authors report the purpose, methods, findings, and conclusions of the study. A key element of writing a research paper is to clearly and objectively report the study's findings in the Results section.
At the end of this section is a sample APA-style research report that illustrates many of these principles. Sections of a Research Report Title Page and Abstract. An APA-style research report begins with a title page. The title is centred in the upper half of the page, with each important word capitalized.
The Results section is a vital organ of a scientific paper, the main reason why readers come and read to. " ". nd new information in the paper. However, writing the"Results section demands a rigorous process that discourages. fi ". many researchers, leaving their work unpublished and uncommunicated in reputable journals.
Tips to Write the Results Section. Direct the reader to the research data and explain the meaning of the data. Avoid using a repetitive sentence structure to explain a new set of data. Write and highlight important findings in your results. Use the same order as the subheadings of the methods section.
Step 1: Consult the guidelines or instructions that the target journal or publisher provides authors and read research papers it has published, especially those with similar topics, methods, or results to your study. The guidelines will generally outline specific requirements for the results or findings section, and the published articles will ...
Use the section headings (outlined above) to assist with your rough plan. Write a thesis statement that clarifies the overall purpose of your report. Jot down anything you already know about the topic in the relevant sections. 3 Do the Research. Steps 1 and 2 will guide your research for this report.
p values. There are two ways to report p values. One way is to use the alpha level (the a priori criterion for the probablility of falsely rejecting your null hypothesis), which is typically .05 or .01. Example: F(1, 24) = 44.4, p < .01. You may also report the exact p value (the a posteriori probability that the result that you obtained, or ...
Abstract. This guide for writers of research reports consists of practical suggestions for writing a report that is clear, concise, readable, and understandable. It includes suggestions for terminology and notation and for writing each section of the report—introduction, method, results, and discussion. Much of the guide consists of ...
Build coherence along this section using goal statements and explicit reasoning (guide the reader through your reasoning, including sentences of this type: 'In order to…, we performed….'; 'In view of this result, we ….', etc.). In summary, the general steps for writing the Results section of a research article are:
The results section of the research paper is where you report the findings of your study based upon the information gathered as a result of the methodology [or methodologies] you applied. The results section should simply state the findings, without bias or interpretation, and arranged in a logical sequence. The results section should always be ...
When to Write Research Report. A research report should be written after completing the research study. This includes collecting data, analyzing the results, and drawing conclusions based on the findings. Once the research is complete, the report should be written in a timely manner while the information is still fresh in the researcher's mind.
Preparation of a comprehensive written research report is an essential part of a valid research experience, and the student should be aware of this requirement at the outset of the project. Interim reports may also be required, usually at the termination of the quarter or semester. Sufficient time should be allowed for satisfactory completion ...
4. Provide a summary of the literature relating to the topic and what gaps there may be. Rationale for study. 5. Identify the rationale for the study. The rationale for the use of qualitative methods can be noted here or in the methods section. Objective. 6. Clearly articulate the objective of the study.
Furthermore, use writing as a tool to reassess the overall project, reevaluate the logic of the experiments, and examine the validity of the results during the research. As a result, the overall research may need to be adjusted, the project design may be revised, new methods may be devised, and new data may be collected.
These guidelines, commissioned and vetted by the board of directors of Language Learning, outline the basic expectations for reporting of quantitative primary research with a specific focus on Method and Results sections. The guidelines are based on issues raised in: Norris, J. M., Ross, S., & Schoonen, R. (Eds.). (2015).
The SQUIRE Guidelines help authors write usable articles about quality improvement in healthcare so that results are findable and widely distributed. SRQR: Standards for reporting qualitative research: a synthesis of recommendations: How to report qualitative research. STARD 2015: STAndards for the Reporting of Diagnostic accuracy
People are described using language that affirms their worth and dignity. Authors plan for ethical compliance and report critical details of their research protocol to allow readers to evaluate findings and other researchers to potentially replicate the studies. Tables and figures present information in an engaging, readable manner.
According to the Pew Research Center, at least 65% of workers prefer to work remotely full-time, and 98% would like to have the option to work remotely at least part of the time.
Since 2020, most research on long Covid has mainly focused on adults. The few studies that tried to analyze pediatric long Covid so far either focused on individual symptoms or focused on adolescents.
Glucagon-like peptide 1 (GLP-1) agonists are medications approved for treatment of diabetes that recently have also been used off label for weight loss. 1 Studies have found increased risks of gastrointestinal adverse events (biliary disease, 2 pancreatitis, 3 bowel obstruction, 4 and gastroparesis 5) in patients with diabetes. 2-5 Because such patients have higher baseline risk for ...
Include relevant statistics. 88% of statistics are made up on the spot (including that one), but people still love them. Data is memorable. Results speak volumes.
Natural Language Processing (NLP) is a subset of artificial intelligence that enables machines to understand and respond to human language through Large Language Models (LLMs)‥ These models have diverse applications in fields such as medical research, scientific writing, and publishing, but concerns such as hallucination, ethical issues, bias, and cybersecurity need to be addressed.
The US NIST has now approved three of the new algorithms being used. Crypto-agility means that a system, platform, application, or organization can rapidly adapt its cryptographic mechanisms and ...